
How to create your own binary format
Programming · Apr 8th, 2025
So you want to serialize data. Chances are you considered some formats already, like JSON, YAML, XAML or something of that sort. Well, what about binary? Don't be scared. A custom binary format isn't that difficult to implement! Sure, there is an initial learning bump, but at the end of this post, you can do this easily yourself. And in terms of size and speed, a custom written serializer easily beats a general one.
I wanted to write this post for quite some time now, but I never wrote my thoughts down. Then my coworker specifically asked me about serialization. So you can thank him for the existence of this post. Thank you Mark :)
The problem
What are we even trying to do? What even is a binary format? Simply put, a binary format is an array of bytes. Nothing more, nothing less. Classes, structs and objects cannot be saved as files. Neither can they be sent over a network. Why that is, is complicated and out of scope of this blog post. (They keyword here is ABI.) Regardless, what is important is that a byte array CAN be saved or sent. So our challenge will be to find a solution, that translates our object into a byte array and back.

Shouldn't be too difficult.
What's a stream?
Before we start with any kind of serialization, we should be talking about streams. We aren't going to modify the byte array directly. That would be cumbersome and difficult. Instead, we are going to use a container known as a "stream". It will make our life so much easier.
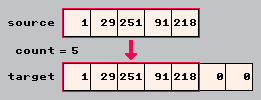
A stream consists of two things: Data and a cursor. The data can be anything: A file, a websocket, a port, whatever. But most importantly for us, the data can be a byte array. The cursor is simply an integer, and it represents the current position in the data. Think of it like the head of a Turing machine. Or the stylus of a record player. I'll use "cursor" and "position" interchangeable from here on. They are pretty much the same concept.

I'll be using the visualization above for all further examples. The boxes represent the data, the byte array, where each cell is a single byte. The red arrow is the cursor, the current position of the stream.
A stream comes with 3 functions: Seek, Read and Write. What these do and how they work in detail, we'll see in a moment. Streams come in many different flavors. Some are read-only, meaning they don't implement Write. Some are write-only, meaning they don't implement Read. For our purposes, we will be using a "MemoryStream". It stores bytes, and it implements all three methods.
Because we will be using a stream in pretty much every example, I want you to understand how a stream works. So we are going to implement one from scratch. It will be barebones, naive and straight forward, but for our use case it will suffice.
All code examples will be in C#, because C# is a language, which Mark can read. If you dear reader have never worked with C# before, then that is fine. We won't be using complicated syntax, so I hope you can follow along.
Let's start by defining our stream:
public class RisMemoryStream
{
private byte[] _data;
private int _position;
public RisMemoryStream()
{
_data = Array.Empty<byte>();
_position = 0;
}
public RisMemoryStream(byte[] value)
{
_data = value;
_position = 0;
}
public byte[] ToArray()
{
return _data.ToArray();
}
// todo:
// seek
// read
// write
}
I prefixed the stream with "Ris", because I am weird and most of the types in my public code are prefixed with the first syllable of my name. It also helps to distinguish my types from others. Anyway, as discussed, the stream consists of two parts: The data and the cursor or position. I also implemented two utility methods, that allow us to create a stream from existing bytes, or to retrieve the bytes once we are done modifying the stream.
We have three more methods to implement. Let's do this!
Seek
Seek does two things: It modifies the position, and then it returns the position after it has been modified. Modifying the position works by adding an offset to one of three locations in the stream:
public enum SeekFrom
{
Begin,
Current,
End,
}
With this, we can implement the Seek method:
public class RisMemoryStream
{
// ...
public int Seek(int offset, SeekFrom seekFrom)
{
switch (seekFrom)
{
case SeekFrom.Begin:
_position = offset;
break;
case SeekFrom.Current:
_position += offset;
break;
case SeekFrom.End:
_position = _data.Length + offset;
break;
default:
throw new ArgumentOutOfRangeException(
nameof(seekFrom),
seekFrom,
null
);
}
// clamp the position, in case it falls out of range
if (_position < 0)
{
_position = 0;
}
if (_position > _data.Length)
{
_position = _data.Length;
}
return _position;
}
}
There are a few things to note here. First, notice how the switch treats SeekFrom differently. When applying an offset to SeekFrom.Begin, the offset is pretty much where you want the position to be. When using SeekFrom.Current, we are simply adding the offset to the current position. When using SeekFrom.End, we are adding the offset from the end of our currently held data.
Using positive and negative offsets, we can walk back and forth in the stream. Due to the clamp however, negative offsets on SeekFrom.Begin and positive offsets on SeekFrom.End have no effect.
Why are we clamping anyway? Well, the allowed range for the position is 0 to _data.Length. The bounds are inclusive. Everything outside that range is invalid. We want the stream to be valid in all cases, and thus we need to prevent the position from falling out of the valid range.
Hold on a sec, doesn't _position == _data.Count mean that our cursor is now pointing outside of our array?

Yes. In this case it does indeed point outside the array. But this is fully intentional. It allows us to get the current length of the stream by calling Seek(0, SeekFrom.End). It also makes reading and writing straight forward. And it also means that when _data is empty, _position being 0 is a valid state.
Clamping is one way to keep the stream valid. Another way would be to throw exceptions, that's what System.IO.MemoryStream does. But I don't like exceptions, so I clamp.
Most commonly, seeking is used like this:
Seek(0, SeekFrom.End)to get to the end to the stream and/or to get its length,Seek(position, SeekFrom.Begin)to set the position directly, andSeek(0, SeekFrom.Current)to get the current position of the cursor
Read
Now let's see how to read from the stream. As a parameter, Read takes an int that specifies how many bytes should be read. It then reads that many bytes, advances the position, and returns the bytes.

Here's the implementation:
public class RisMemoryStream
{
// ...
public byte[] Read(int count)
{
// clamp to ensure enough bytes to read
var bytesLeftToRead = _data.Length - _position;
if (count > bytesLeftToRead)
{
// not enough bytes
// only read whats left
count = bytesLeftToRead;
}
// read the bytes, by copying them to a new array
var bytes = new byte[count];
Array.Copy(
_data, // source
_position, // source index
bytes, // target
0, // target index
count // count
);
// advance the cursor
_position += count;
return bytes;
}
}
First, we are clamping count. Then we copy the requested number of bytes into a new array. At last, but not least, we update the position and return the read bytes.
Copy operations can be a bit intimidating for new programmers. I hope the example below clarifies things a bit better:

Let's talk about the clamp for a moment. It is there specifically to prevent client code to read more bytes than are actually left in the stream. Reading more bytes than are present is an invalid operation, and we must decide what to do in such a case. Clamping like this provides valid default behavior, but requires client code to validate, if as many bytes were read as expected. Another viable approach would be to throw an exception. The exception comes with the benefit, that no operation will take place. My implementation above will always allocate an array and copy into it, regardless if the operation is sensical or not. But clamping has the benefit that you can read all remaining bytes by calling Read(int.Max) on our stream.
You may have also noticed that I am returning an array. You may find that common stream implementations pass an array as a parameter instead, expecting the read method to fill it. This is done to prevent unnecessary allocations. My implementation will allocate an array for every single read operation that you will make. But the tradeoff is that client code will be significantly simpler. If you want, as homework, you can try to rewrite the read method such that it will take an array as a parameter. Its signature should look like this:
public int Read(byte[] buffer, int count)
The returned int is to indicate how many bytes were actually read. Whether you opt for a clamped- or exception-based error behavior (to prevent too many bytes being read), even a successful read may not fill your entire array. So make sure to return an int to notify the client code.
Before we continue, I again want to stress that _position == _data.Count is a valid state, in which our stream can find itself in. Assume for a moment that it wasn't, how would you determine if there are bytes left to read?

If we allow _position == _data.Count to be valid, then things become very easy:

Write
Two of three methods implemented. Now let's look at Write. Write puts bytes into the stream at the position of the cursor, and then advances the cursor.

Notice that writing can both grow the stream, as well as overwrite existing bytes.
I want to stress one last time that _position == _data.Count is completely valid. If the cursor is at the very last position of the stream, then being outside the array allows us to append to the stream without overwriting anything:

This also allows appending onto an empty stream, without compensating for any edge cases when implementing it. _position == _data.Count is indeed a very useful hack and very useful behavior a stream can have.
Enough yapping, let's see the implementation:
public class RisMemoryStream
{
// ...
public void Write(byte[] value)
{
// ensure the capacity is big enough
var requiredCapacity = _position + value.Length;
if (_data.Length < requiredCapacity)
{
// capacity is not big enough
// create an array that is big enough
// copy the old into the new one
var newDataArray = new byte[requiredCapacity];
Array.Copy(
_data, // source
newDataArray, // target
_data.Length // count
);
_data = newDataArray;
}
// write by copying the values into the array
Array.Copy(
value, // source
0, // source index
_data, // target
_position, // target index
value.Length // count
);
// advance the cursor
_position += value.Length;
}
}
First, we check whether our stream has enough bytes left to hold the data. If not, we must grow it. This is done by allocating a new array, which is big enough to hold all data, and then copying the old array into the new one. Then, we can copy the actual value into our data array.
Again, copy operations may intimidate the new programmer, so let's visualize them too. Here's an example for resizing the array:
And here is an example for copying the value into the array:

And that's it. This is everything that we are going need. A full implementation can be found here: LINK
You may have noticed that I did not implement the base class. This is on purpose. I am targeting the lowest denominator of readers, and System.IO.Stream is a tad too complicated for my taste. Also, we don't need the entire thing for the following chapters. The methods we have are enough for our use case.
If you are feeling confident in your ability, I leave the implementation of System.IO.Stream as homework for you. Implementing the base class comes with the obvious benefit, that you can use all utility methods for streams on your stream as well.
I am going to use RisMemoryStream for the following chapters. You are allowed to use your stream from your homework. You are also allowed to use System.IO.MemoryStream from the standard library, which has a much more sophisticated implementation, with all the bells and whistles.
Serialization: Baby Steps
Let me introduce you to a new static class:
public static class RisIO
{
public static int Seek(RisMemoryStream s, int offset, SeekFrom seekFrom)
{
return s.Seek(offset, seekFrom);
}
public static byte[] ReadUnchecked(RisMemoryStream s, int count)
{
return s.Read(count);
}
public static byte[] Read(RisMemoryStream s, int count)
{
var result = ReadUnchecked(s, count);
if (result.Length != count)
{
throw new ArgumentOutOfRangeException(
nameof(count),
count,
null
);
}
return result;
}
public static void Write(RisMemoryStream s, byte[] value)
{
s.Write(value);
}
}
You may be asking: Is it really necessary to wrap these methods? No, it isn't necessary. But I like to have a uniform API. By wrapping them, regardless if we are reading/writing raw bytes or values like ints and floats, the calls will always look very similar: RisIO.ReadX(stream) or RisIO.WriteX(stream, value). (This will be especially true when we are modifying them a bit later.)
Notice however, that I am throwing an exception in the read method. That is because Read represents a checked operation, meaning it must produce an error if things don't go as expected. Unfortunately, error handling is difficult. And C# is not Rust. So despite me not being the biggest fan of exceptions, I will be falling back to them when the situation calls for it. ReadUnchecked does no checks, and thus client code is at the mercy of whatever error handling the underlying stream uses. Read is a safe alternative. Also notice that Read does not catch the exception of the underlying stream. That is intentional, because exception is exception, regardless of who threw it. In any case, the client is notified on an error, which is good enough for us.
For you C++ nerds out there, yes, this isn't strongly exception safe. If you know what I mean by this, then you are clearly above my target audience. I leave it as a challenge for the reader to argument why it doesn't fulfill the strong exception safety guarantee.
I think strong exception safety isn't of importance here, as I consider any exception a failed deserialization. I like my programs to burn and crash on a (truly) unexpected error. We will generate streams on the fly, and none should outlive a serialization operation. If this bothers you, you can write strong exception safe implementations for this and all the coming methods. I will stick with simpler implementations, even if they are less rigorous.
Integers
Now let's serialize some data! Took us quite a while.
Since classes and structs are made from smaller types, let's see how these smaller types are serialized. Starting with the humble integer. On most platforms, including C#, an int is made up of 32 bits or 4 bytes. So all we need to do is to retrieve these 4 bytes and then put them into our read/write methods. That should be easy. Right?
Jump scare: Endianness
Immediately, even before we serialize our first thing, we are met with an obstacle. Unfortunately, this won't be our last 😓
So what is endianness? Let me answer that question with an example and another question: The int 730797131 is comprised of the bytes 43, 143, 20 and 75. Now, in which order should we store it?
43, 143, 20, 75
Or?
75, 20, 143, 43
As it turns out, both approaches are valid and reasonable. So now we are left to choose. Of course we could also scramble them, but that assumes that we know in which order the unscrambled bytes should be. You see, this is a CPU problem, and endianness determines in what byte order different CPUs represent a number. We must solve this. Chances are, that our binary format is stored as a file or sent as a package over the internet, read by a different computer that has a different endianness.
Since there are two orders, there are two types of endianness: Big-endian and little-endian. To figure out which is which, we need to look at the first and the last byte of our number. Sticking with the example 730797131, then 43 is the "most significant byte" (MSB) and 75 is the "least significant byte" (LSB). 43 is the MSB, because it has huge effect on the number. On the other hand, 75 is the LSB, because it has little effect. Look at what happens to 730797131 when you add 1 to either the MSB or LSB:
43, 143, 20, 75 => 730797131
43, 143, 20, 76 => 730797132
44, 143, 20, 75 => 747574347
Adding 1 to the LSB only adds 1 to the whole number. Adding 1 to the MSB however adds 2^24, which equals 16777216!
Here's why that's important: If you store the MSB first, you are using big-endian. If you are storing the LSB first, then you are using little-endian. A good way to remember this: If you are storing the big byte first, you are using big-endian.
: ^)
What you choose is up to you. But whatever you do, stay consistent. Most modern mainstream CPUs use little-endian. But there exist exceptions, notably embedded systems. Older hardware might also use big-endian.
Let's see how this actually looks like in code:
public static class RisIO
{
// ...
public static int ReadInt(RisMemoryStream s)
{
var bytes = Read(s, 4);
FixEndianness(bytes);
var result = BitConverter.ToInt32(bytes);
return result;
}
public static void WriteInt(RisMemoryStream s, int value)
{
var bytes = BitConverter.GetBytes(value);
FixEndianness(bytes);
Write(s, bytes);
}
public static void FixEndianness(byte[] value)
{
// we are using little-endian
// if our cpu is not little-endian, flip the bytes
if (!BitConverter.IsLittleEndian)
{
Array.Reverse(value);
}
}
}
Whenever you are dealing with raw bytes, you must keep endianness in mind. If you have ever read a spec before, which deals with raw bytes, then you know that they always mention what endianness their format uses. Well, at least every spec I've ever read mentioned it. Also, you can directly toggle endianness in most hex editors.
Hex editors
Speaking of hex editors, when writing your own binary format, you should probably start using one. To debug your binary format, you can simply write your serialized bytes into a file and then open that file with the hex editor of your choice. On windows I am using HxD, and on Linux I am using Okteta.
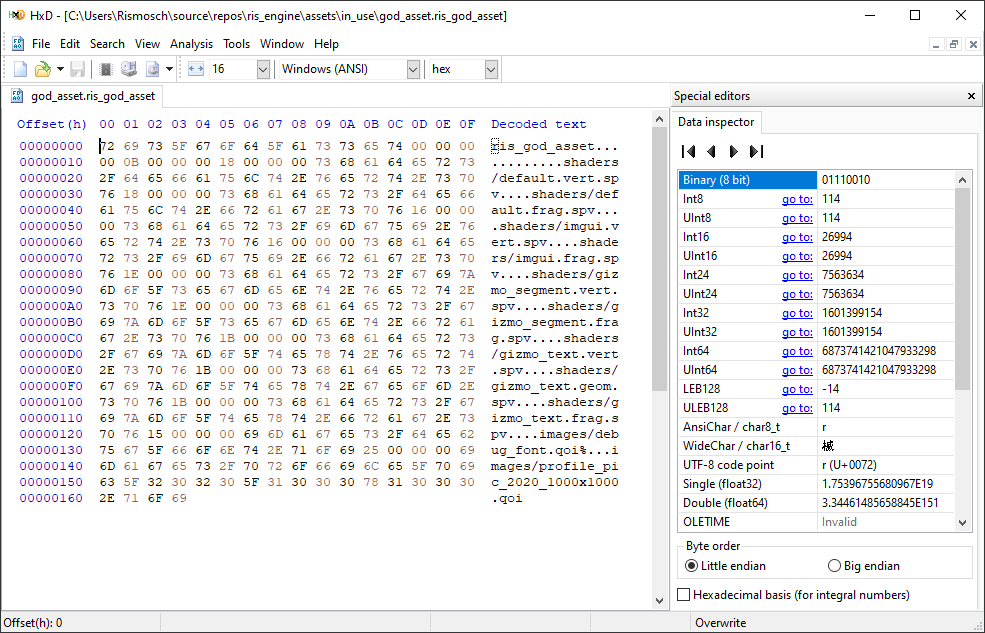
Some hex editors have more features, some less, but most are split into 3 views. On the left you can view the actual bytes in hexadecimal. Also there are the offsets displayed in hexadecimal as well, to ease navigating large files and locating specific bytes at certain positions.
Right next to it, there is a decoded text interpretation. Most of the time, this is some form of ASCII. This decoding is mostly useful when your format uses text. If you are not storing text, the decoded text will be scrambled nonsense. But often the text can help you to spot patterns.
I assume that's why little-endian is practically the standard for modern CPUs. Small integers have their MSB set to 0. If you use little-endian, then it's easy to spot at a glance, where that integer begins. But that is pure conjecture on my part.

On the right side of the hex editor, you will usually find an inspector, which provides gazillions of interpretations of the currently selected byte. It may read multiple bytes to come to each interpretation. After all, the hex editor doesn't know how your binary format works, so it displays all the possibilities. You can toggle endianness and see how the values in the inspector change.
Floats and other numbers
Endianness was quite the big jump scare. But once we are aware of it, floats are very straight forward:
public static class RisIO
{
// ...
public static float ReadFloat(RisMemoryStream s)
{
var bytes = Read(s, 4);
FixEndianness(bytes);
var result = BitConverter.ToSingle(bytes);
return result;
}
public static void WriteFloat(RisMemoryStream s, float value)
{
var bytes = BitConverter.GetBytes(value);
FixEndianness(bytes);
Write(s, bytes);
}
}
As you can see, the implementation is very similar to that of the integer. I won't list the implementations for all the other numeric types here. If you need to read/write single bytes, chars, doubles, shorts or longs, whether they are signed or not, I am sure you can figure out the correct implementation on your own.
Or you can ask an LLM to do that for you. I heard they are the hot craze right now. Not that I would endorse such steaming shit...

Enums
As far as I am aware, most programming languages use integers for enums internally, including C#. A notable exception is Rust, where an enum is more akin to a union type, which we will come back to later.
An enum value is just a tag to the compiler, which improves readability for you the programmer. But behind the scenes it's just a number. As such, writing an enum is as easy as converting it to an int and writing that:
public static class RisIO
{
// ...
public static void WriteEnum(RisMemoryStream s, Enum value)
{
var i = Convert.ToInt32(value);
WriteInt(s, i);
}
}
Since we are using WriteInt to write the number, all endianness problems are already taken care of <3
Reading is done like so:
public static class RisIO
{
// ...
public static T ReadEnum<T>(RisMemoryStream s) where T : Enum
{
var i = ReadInt(s);
if (!Enum.IsDefined(typeof(T), i))
{
throw new FormatException(
$"{i} is not defined for enum {typeof(T)}"
);
}
var result = (T)Enum.ToObject(typeof(T), i);
return result;
}
}
The code above uses the most advanced syntax of all the examples in this post, because it makes use of generics. If you are not familiar with generics, think of them like this: This method accepts any enum. Now instead of using the specific enum type, T represents every enum possible. No matter what enum you read from this method, the method will resolve it correctly.
Don't worry, we'll walk through this example: First, we read an int. Then we check if the enum is actually defined for that int. If it isn't, we throw an exception. If it is defined, we cast it to the enum and return it.
Instead of throwing an exception, you could return a default value. But I prefer the exception here, because a default value would obfuscate invalid data.
It should be noted, that this approach only works for enums that have unique values. Consider the following enum:
public enum Fruit {
Apple = 1,
Banana = 2,
Orange = 3,
MyFavorite = 3,
}
In this case, when writing Fruit.MyFavorite into the stream, you might read Fruite.Orange out of it. This may be desirable, or it may not. In case it is not desirable, you need to read and write strings instead of ints. How to serialize a string we'll see later.
Booleans
Now let's take a look at booleans. A bool can only have 2 values! true and false! How hard can that be? This will be easy!
Narrator: It will not be easy.
New programmers are often surprised to hear that booleans are stored as 1 or more bytes in memory, instead of 1 bit. If you didn't know this, now you know :) The reason why is, because the CPU cannot access single bits. A CPU operates in "words" which are 1 or multiple bytes long.

With our serialization, we face a similar reality: With our current API, we can only serialize bytes, not bits. So whenever we want to save a bool, we waste at least 7 bits of space.
This may seem wasteful, but from my experience, this is a problem which you usually don't want to solve. As it stands, our serialization is "byte aligned", which means all chunks of information start and end with a byte. Once you introduce variable bitlength into your serialization, you face alignment issues. And I cannot stress enough that this is a major pain in the ass, and it really isn't worth solving.
To more effectively use all the space, there are 2 valid approaches: The first one is compression. We will talk about that at the very end of this post. The second is bitfields.
A byte consists of 8 bits. Since a bool only requires 1 bit, it directly follows, that a single byte can hold 8 bools. An int has 32 bits, so it can hold 32 bools! A bitfield is a technique to store bools in an integer. Using bit shift operations and masks you can set, clear and read specific bits and treat them as bools.
However, bitfields are tricky. And the syntax seems arcane for the uninitiated.

I don't recommend a new programmer to deal with bitfields, as they are very easy to misuse. They are so tricky in fact, that Rust, the programming language with possibly the strictest type system of all available languages currently available, doesn't have a type for them. Instead, Rust users recommend external libraries that do bitfields for you.
You can read up on bitfields if you want to, but I will consider any further discussion to be out of scope for this post. If you want to read up on yourself, here's an Wikipedia article and this amazing video by Creel.
My recommendation is, even if it's wasteful, to store an entire byte for a single bool. So we will continue with that.
Ok, but oh no. We are not done yet with problems: What even is a bool? Like, how does the CPU actually represent that in memory? The unfortunate answer is, that bools do not exist. Yes, you read that correctly. As far as the CPU is concerned, only words exist. At best, some special registers that store flags could be considered boolean, but they are used for a completely different use case, compared to the bools in your code. And unless you are writing assembly, you can't actually manipulate such flag registers.
Different programming languages compile bools differently. If you've ever tried to write interoperability between two programming languages, you might have run into this. But it gets worse: Not even the SAME programming language can agree on how a bool should be represented. Different C compilers may produce different assembly. Newer C standards only define what behavior a bool should have, not how it should be represented in memory.
Wild, isn't it?
This absolute disaster has direct consequences for our serialization: Even if our programming language provides a method to convert a bool to bytes and vice versa, we cannot rely on it. There is no guarantee that a different computer or a different program can understand our bool. As such we must take the serialization of bools into our own hands. Luckily, this isn't difficult, as a bool can hold only 2 different values.
There are many different strategies we could use here. We could use a bitfield, but as discussed, not recommended. Instead, I suggest to write a 1 when the bool is true, and 0 when the bool is false. When reading, 1 means true, 0 means false, and every other value leads to an exception.
If you want, you can use a different strategy. But whatever you do, make sure that it is consistent over all computers and programs that use your binary format.
Here's my implementation:
public static class RisIO
{
// ...
public static bool ReadBool(RisMemoryStream s)
{
var bytes = Read(s, 1);
var b = bytes[0];
switch (b)
{
case 1:
return true;
case 0:
return false;
default:
throw new FormatException(
$"{b} is not a valid bool"
);
}
}
public static void WriteBool(RisMemoryStream s, bool value)
{
if (value)
{
Write(s, new byte[] { 1 });
}
else
{
Write(s, new byte[] { 0 });
}
}
}
Classes and structs
We have come quite far. So much so, that we can start to serialize our classes and structs! Classes are ultimately just a list of smaller types (we are not going into what methods are or how they work, for that you can look up vtables). So, reading and writing this "field list" in a predefined order is enough to serialize our class. This is very easy actually. Here's an example:
public class MyAwesomeClass
{
public int MyNumber;
public float MyOtherNumber;
public bool MightNotBeTrue;
public byte[] Serialize()
{
var s = new RisMemoryStream();
RisIO.WriteInt(s, MyNumber);
RisIO.WriteFloat(s, MyOtherNumber);
RisIO.WriteBool(s, MightNotBeTrue);
return s.ToArray();
}
public static MyAwesomeClass Deserialize(byte[] value)
{
var s = new RisMemoryStream(value);
var result = new MyAwesomeClass();
result.MyNumber = RisIO.ReadInt(s);
result.MyOtherNumber = RisIO.ReadFloat(s);
result.MightNotBeTrue = RisIO.ReadBool(s);
return result;
}
}
Very straight forward. Very simple. This is what I meant by "creating your own binary format is fast and easy". Sure, there was a somewhat steep learning curve. But once you understand these ideas, and have a collection of utilities like RisIO, you can whip out a new binary format for everything in no time.
What do you say? I did not cover arrays? Strings? Pffff whaat? Who needs those? I certainly don't need arrays. That's for certain. No! Don't look at the scrollbar! We are practically done...
Sized vs unsized types
Welp. We are not, in fact, done. As it turns out there is quite a bit more to cover. But it is true though: Serializing classes and structs is as easy as calling the according IO methods in a predefined order. Everything from here on out covers special types that require specific strategies. It all boils down to sized vs unsized types.
Up until this point, we have only seen sized types. By that I mean, we know how big they are, how much memory they take up. A serialized int has always a size of 4 bytes. A serialized bool is always 1 byte. Last jump scare, I promise: There exist types with unknown sizes.
Let's take the array for example. How many bytes does an array take up? Think about it for a second. The answer is: It depends. If there are no elements in the array, then hurray, we don't need any memory actually. But if there are, idk, 10 items in it, then we require at least 10 times the size of whatever type we are storing.
This is what I mean by an unsized type. An unsized type is a type, that we don't know the size up front. To be specific: A type is unsized, if it's size cannot be determined at compile time.
Once our program runs and the array is actually loaded into memory, it does take up space. This means it does actually have a size, but it must be determined at runtime. To properly serialize an array, we need to store the number of elements, and then serialize each element individually.
Here's how that might look like:
public class MyMostFavoriteBools
{
public List<bool> Bools;
public byte[] Serialize()
{
var s = new RisMemoryStream();
RisIO.WriteInt(s, Bools.Count);
foreach (var b in Bools)
{
RisIO.WriteBool(s, b);
}
var result = s.ToArray();
return result;
}
public static MyMostFavoriteBools Deserialize(byte[] value)
{
var s = new RisMemoryStream(value);
var result = new MyMostFavoriteBools();
result.Bools = new List<bool>();
var count = RisIO.ReadInt(s);
for (var i = 0; i < count; ++i)
{
var b = RisIO.ReadBool(s);
result.Bools.Add(b);
}
return result;
}
}
You may notice that these are methods directly on the class itself, instead of RisIO. Well, at the time of writing this post, I have not found a satisfying method signature that covers all the ergonomics that I want in a standalone IO method. As such, I typically serialize arrays like the example above, even if it may be verbose at times.
It should be noted, that often times, classes and structs are sized types as well. If you know the sizes of the fields, then you know the size of the entire class. For example, a class storing an int, a float and a bool has always the size of 4 + 4 + 1 = 9 bytes. As such, it too can easily be stored in an array.
However, once a class stores even a single unsized type, the class will be unsized itself. More often than not, this is fine. Elements in an array are stored back-to-back. Reading one element after the other gives correct results, even if the array element is unsized. But it should be noted that you must deserialize ALL array elements in such a case. You cannot, for example, skip every second element via Seek(n, SeekFrom.Current), because you don't know the size of an element. If you absolutely need this behavior, then you can store the size first, and serialize the class second. The reader should read the size first, and then decide if it wants to skip or not.

Strings
Now we can finally serialize strings. Took us long enough.
I often see new programmers, who work with modern programming languages, taking strings for granted. Some even consider them to be a primitive type!
"Come on man. How hard can Strings possibly be?"
As it turns out, strings are very difficult. If you've ever worked with strings in C before, you know how non-primitive they actually are. Rust has hundreds of different string types! Well, I am exaggerating, but Rust indeed has a lot of different types of strings.

But even if we stay in the realm of C#, strings might still be tricky. Plain text isn't as plain text as you might think. "Plain Text" by Dylan Beattie is a good talk I recommend: LINK. Another good resource is "The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)" by Joel Spolsky: LINK. The rabbit hole goes quite deep, and strings are anything but simple.
But there are very good news for us: Practically, strings are a solved problem.
Thanks to Unicode, serialization of strings is actually very straight forward (as long as we stick with Unicode). To keep things brief, and to summarize Joels post, a string is a sequence of characters. Each character is defined by a codepoint. Codepoints are arbitrarily defined, and must be "encoded" before they can be stored in memory. As long as we know what encoding a given string uses, we can read and understand it.
There are many different encodings, but as long as we use the same encoding in the serialize and deserialize methods, we will be fine. I choose UTF-8, because it is ubiquitous. You don't need to know how UTF-8 works, but you can read up on it if you want. Here's a Wikipedia article, here's the official RFC and here's Tom Scott on Computerphile.
Since strings are a solved problem, serialization is stupidly easy for us:
public static class RisIO
{
// ...
public static string ReadString(RisMemoryStream s)
{
var length = ReadInt(s);
var bytes = Read(s, length);
var result = Encoding.UTF8.GetString(bytes);
return result;
}
public static void WriteString(RisMemoryStream s, string value)
{
var bytes = Encoding.UTF8.GetBytes(value);
WriteInt(s, bytes.Length);
Write(s, bytes);
}
}
Instead of serializing characters, we first encode our string into UTF-8 bytes and then store that as a dynamic array. We are storing the length first and then the bytes. To deserialize a string we read the length first and read that many bytes, which are then interpreted as a UTF-8 string and converted into a C# string. Easy :)
In case it isn't obvious, strings are unsized types, because they can have arbitrary lengths.
Dynamic types
Another kind of unsized types are dynamic types, i.e. types that are only known during runtime. Notable examples include polymorphism, by which I mean multiple classes that implement the same base class. This is very common in OOP languages. In other languages union structs fall into the same problem, like Rust enums for example. Here's some code to work with:
public class Fruit { /* ... */ }
public class Apple : Fruit { /* ... */ }
public class Banana : Fruit { /* ... */ }
public class Orange : Fruit { /* ... */ }
public class FruitBasket
{
public List<Fruit> Fruits;
// ...
}
Here, Fruit is an unsized type, because any derivation may serialize to a different length. An Apple might serialize differently than an Orange for example. But because of polymorphism, both can be stored in the same List of FruitBasket.Fruits. So we don't know at compile time how much memory a FruitBasket would take up.
To solve this, we store the type as an enum and serialize based on that. This works:
public enum FruitKind
{
Apple,
Banana,
Orange,
}
public abstract class Fruit
{
public abstract FruitKind GetKind();
public abstract byte[] Serialize();
}
public class Apple : Fruit
{
public override FruitKind GetKind()
{
return FruitKind.Apple;
}
public override byte[] Serialize()
{
// ...
}
public static Apple Deserialize(RisMemoryStream s)
{
// ...
}
}
public class Banana : Fruit
{
public override FruitKind GetKind()
{
return FruitKind.Banana;
}
public override byte[] Serialize()
{
// ...
}
public static Banana Deserialize(RisMemoryStream s)
{
// ...
}
}
public class Orange : Fruit
{
public override FruitKind GetKind()
{
return FruitKind.Orange;
}
public override byte[] Serialize()
{
// ...
}
public static Orange Deserialize(RisMemoryStream s)
{
// ...
}
}
public class FruitBasket
{
public List<Fruit> Fruits;
public byte[] Serialize()
{
var s = new RisMemoryStream();
RisIO.WriteInt(s, Fruits.Count);
foreach (var fruit in Fruits)
{
var kind = fruit.GetKind();
RisIO.WriteEnum(s, kind);
var bytes = fruit.Serialize();
RisIO.Write(s, bytes);
}
var result = s.ToArray();
return result;
}
public static FruitBasket Deserialize(byte[] value)
{
var result = new FruitBasket();
result.Fruits = new List<Fruit>();
var s = new RisMemoryStream(value);
var count = RisIO.ReadInt(s);
for (var i = 0; i < count; ++i)
{
var kind = RisIO.ReadEnum<FruitKind>(s);
Fruit fruit;
switch (kind)
{
case FruitKind.Apple:
fruit = Apple.Deserialize(s);
break;
case FruitKind.Banana:
fruit = Banana.Deserialize(s);
break;
case FruitKind.Orange:
fruit = Orange.Deserialize(s);
break;
default:
throw new ArgumentOutOfRangeException();
}
result.Fruits.Add(fruit);
}
return result;
}
}
Whenever a Fruit is serialized, we first get its FruitKind and store that first. Then we serialize the Fruit afterwards. When reading, we read the FruitKind first. Using a switch, depending on the FruitKind we are either deserializing an Apple, a Banana or an Orange.
Notice how Deserialize of each Fruit takes a RisMemoryStream instead of a byte[]. This is different from previous examples. The reason for that is because FruitBasket does not know how big a serialized Fruit is. By passing the stream into Fruits deserialization, the Fruit can read as many bytes as it needs.
An odd problem with a banger solution
We are slowly inching closer to the end of this post. So let me present you with an odd, maybe somewhat complicated problem. Up until now, we haven't really used Seek, did we? Well, in this chapter we are going to use it. And for a very cool reason actually. So cool in fact, that I hope this chapter blows your mind.
Let's say you have three classes: FooBase, FooA and FooB. FooBase stores a FooA and a FooB. Assume FooA and FooB have according serialize- and deserialize methods. FooBase looks like this:
public class FooBase
{
public FooA A;
public FooB B;
public byte[] Serialize()
{
var bytesA = A.Serialize();
var bytesB = B.Serialize();
var s = new RisMemoryStream();
RisIO.Write(s, bytesA);
RisIO.Write(s, bytesB);
var result = s.ToArray();
return result;
}
public static FooBase Deserialize(byte[] value)
{
var result = new FooBase();
var s = new RisMemoryStream(value);
result.A = FooA.Deserialize(s);
result.B = FooB.Deserialize(s);
return result;
}
}
Nothing too complicated. Looks kinda like the example in the "Classes and structs" chapter.
But here's my request: I have a stream that contains a serialized FooBase, but I only want to read FooB out of it.
This may seem like an odd request, but let's roll with it. Maybe FooA is very big and very costly to deserialize, so I only want to deserialize FooB and deal with FooA some time later. I don't want to deserialize the entire FooBase, when I just need FooB. How would you implement this?
Well, we definitely need to change both Serialize and Deserialize. As it stands now, our binary format stores no information on where FooB starts in the stream. Currently we have to deserialize FooA, which advances the stream in such a way, that FooB can be deserialized.
One thing we can do, is to store the length of FooAs bytes right before it:
public class FooBase
{
public FooA A;
public FooB B;
public byte[] Serialize()
{
var s = new RisMemoryStream();
var bytesA = A.Serialize();
var bytesB = B.Serialize();
RisIO.WriteInt(s, bytesA.Length); // store length
RisIO.Write(s, bytesA);
RisIO.Write(s, bytesB);
var result = s.ToArray();
return result;
}
public static FooBase Deserialize(byte[] value)
{
var result = new FooBase();
var s = new RisMemoryStream(value);
RisIO.Seek(s, 4, SeekFrom.Current); // skip length
result.A = FooA.Deserialize(s);
result.B = FooB.Deserialize(s);
return result;
}
}
This way, we have information on how big FooA actually is. So we can use it to skip FooA entirely. Here's how that would look like:
public class FooBase
{
// ...
public static FooB DeserializeOnlyB(byte[] value)
{
var s = new RisMemoryStream(value);
var bytesLengthA = RisIO.ReadInt(s);
RisIO.Seek(s, bytesLengthA, SeekFrom.Current);
var result = FooB.Deserialize(s);
return result;
}
}
Easy. Read the length, and skip that many bytes forward.
I am not satisfied with this solution however. What if we also have FooC, FooD, and so on? If we have thousands of Foos, and we only want to deserialize the last one, then we need to read and skip thousand lengths!
No, I have a better idea: Instead of storing the length of FooA, let's store the position of FooB:
public class FooBase
{
public FooA A;
public FooB B;
public byte[] Serialize()
{
var s = new RisMemoryStream();
// placeholder
RisIO.WriteInt(s, 0);
// serialize A
var bytesA = A.Serialize();
RisIO.Write(s, bytesA);
// serialize B
var positionB = RisIO.Seek(s, 0, SeekFrom.Current);
var bytesB = B.Serialize();
RisIO.Write(s, bytesB);
// go back to placeholder and write the actual position
RisIO.Seek(s, 0, SeekFrom.Begin);
RisIO.WriteInt(s, positionB);
var result = s.ToArray();
return result;
}
public static FooBase Deserialize(byte[] value)
{
var result = new FooBase();
var s = new RisMemoryStream(value);
RisIO.Seek(s, 4, SeekFrom.Current); // skip position
result.A = FooA.Deserialize(s);
result.B = FooB.Deserialize(s);
return result;
}
// ...
}
With this, we can directly jump to FooB:
public class FooBase
{
// ...
public static FooB DeserializeOnlyB(byte[] value)
{
var s = new RisMemoryStream(value);
var positionB = RisIO.ReadInt(s);
RisIO.Seek(s, positionB, SeekFrom.Begin); // jump to B
var result = FooB.Deserialize(s);
return result;
}
}
This works. And it is actually quite useful. I use this technique in ris_engine, in which I store all assets in a single file. At the beginning of the asset file, there is a lookup where each asset is stored. Loading an asset is as simple as seeking to the position of the according asset and reading from there. It's also quite helpful if you have quite complicated structs with many unsized types. Storing positions like this is quite the game changer.
And this is where I pull the rug from under you.
If you understood this concept of positions, then congratulations. You now understand pointers.
I am not kidding. This is no joke and I am fully serious. New programmers often struggle with pointers as a concept. From my experience, they even show pride in their unwillingness to understand what a pointer is. The argument I often hear is, that they don't intend to write C/C++, and therefore, pointers are not required to be understood.
But I want to stress again, this position concept we just implemented, is exactly what a pointer is. Somewhere in our stream FooB is stored. At the start of the stream, we have written a pointer, which tells us exactly where FooB is. To read FooB, we use the value of the pointer to seek to the position where FooB actually sits.
The same concept applies to actual pointers in languages like C/C++ and Rust. If you store a simple variable, you have direct access to it. You can read, modify and use it. No pointers required. If you have a pointer however, that variable sits somewhere in memory. Think of memory as a very long byte array, just like our stream. The pointer simply stores an index into that long byte array. To look up the value of our pointer, we look in the array at that index and voilà, we know what our pointer stores.
When people talk pointers, they often say "address" instead of "index". And people say "dereference" instead of "lookup".
| pointer | stream | array |
|---|---|---|
| address | cursor / position | index |
| dereference | read / write | lookup |
I hope you could follow me. I think this was fun. And you can pat yourself on the back, for finally being able to understand pointers.
From now on, it's smooth sailing. The heavy lifting has been done. All that's left is to improve a bit on what we've learned and then discuss some useful strategies.
Making it fat
While we are at pointers now, I want to use the opportunity to widen your mind a little bit.
Right now, when storing a pointer, we are storing just a position. While this is sufficient, if misused, it can produce all kinds of headaches. Like, nothing stops the serializer to read and write outside our intended region. This may cause unintended bugs, but it can also be abused by mischievious actors. As a matter of fact, some of my previous deserialize code does allow such a bug. The astute reader may have caught it already.
Let me bring up the code again, so you have another chance to find it:
public class FooBase
{
// ...
public static FooB DeserializeOnlyB(byte[] value)
{
var s = new RisMemoryStream(value);
var positionB = RisIO.ReadInt(s);
RisIO.Seek(s, positionB, SeekFrom.Begin); // jump to B
var result = FooB.Deserialize(s);
return result;
}
}
Did you catch it? It may be hard to spot, since we are missing a crucial implementation, but the problem is right there. The fruits example from earlier suffers from the same bug actually...
As it stands now, the code is assuming that FooB.Deserialize never seeks, or at least seeks in a way that is invisible to FooBase. Since FooB.Deserialize takes the entire stream as an input, it can seek, read and write wherever it wants, even outside its intended range.

Now we are reading in some place outside of our intended area, which is not good.
This error is called an out-of-bounds error, and it is one of the many reasons why C and C++ are considered unsafe. Pointers in C and C++ are just addresses, and nothing stops you from accessing any memory you want. You can dereference before and after your pointer willy nillingly.
To prevent such out-of-bound accesses, modern programming languages simply don't allow it. C# for example throws an exception if you try to access an array out of bounds. Not all hope is lost for C and C++ though, as modern operating systems utilize some clever tricks, like memory paging. But that's more of a band aid than an actual solution.
In our case, we want to prevent the deserializer to access an entire stream. We don't want it to modify the stream however it likes. The easiest way to accomplish this is to simply not give our serializer a stream, and only rely on byte arrays. But this implies that the one creating the array knows how many bytes a given deserializer needs. In one way or another, we have to store the length of our bytes somehow.
Let me introduce you to the FatPtr. The FatPtr is a fairly simple struct that stores two ints: An address and a length. The address is, well, the address. And the length describes how long the byte array at that address is. Since a normal pointer only stores a position, a FatPtr is "fat", because it stores a length as well.
public struct FatPtr
{
public int Address;
public int Length;
public FatPtr()
{
Address = 0;
Length = 0;
}
public static FatPtr WithLength(int address, int length)
{
if (length < 0)
{
throw new ArgumentOutOfRangeException(
nameof(length),
length,
null
);
}
var result = new FatPtr();
result.Address = address;
result.Length = length;
return result;
}
public static FatPtr WithEnd(int begin, int end)
{
if (begin > end)
{
throw new ArgumentOutOfRangeException(
nameof(end),
end,
null
);
}
var result = new FatPtr();
result.Address = begin;
result.Length = end - begin;
return result;
}
public int End()
{
return Address + Length;
}
public bool IsNull()
{
return Address == 0 && Length == 0;
}
}
This implementation also introduces some utility methods, which will be helpful later. For example, we can construct a FatPtr via a beginning and an end. We also define that Address == 0 && Length == 0 means that we are dealing with a null pointer, which might be helpful in some instances. For example, if a field in our data class can be something or nothing, we can use a null pointer to indicate that the field stores nothing.
To support FatPtrs, let's introduce two new methods to RisIO:
public static class RisIO
{
// ...
public static FatPtr ReadFatPtr(RisMemoryStream s)
{
var address = ReadInt(s);
var length = ReadInt(s);
var result = FatPtr.WithLength(address, length);
return result;
}
public static void WriteFatPtr(RisMemoryStream s, FatPtr value)
{
WriteInt(s, value.Address);
WriteInt(s, value.Length);
}
}
The FatPtr only stores two fields, so to serialize a FatPtr we only need to serialize these two fields. And while we are at it, let's modify the regular RisIO.Write method like so:
public static class RisIO
{
// ...
public static FatPtr Write(RisMemoryStream s, byte[] value)
{
var begin = Seek(s, 0, SeekFrom.Current);
s.Write(value);
var end = Seek(s, 0, SeekFrom.Current);
var ptr = FatPtr.WithEnd(begin, end);
return ptr;
}
}
We seek before and after the write, and construct a FatPtr to it. This FatPtr then points exactly at where we have just written some bytes. This significantly improves the ergonomics of client code, as we will see in the example. But before we take a look at that example, I want to add one last little helper to our RisIO toolbox:
public static class RisIO
{
// ...
public static byte[] ReadAt(RisMemoryStream s, FatPtr fatPtr)
{
Seek(s, fatPtr.Address, SeekFrom.Begin);
var result = Read(s, fatPtr.Length);
return result;
}
}
This method takes a FatPtr, which it uses to determine where to seek to and how many bytes should be read. This also will come in handy.
With these tools under our belt, we can now implement a safe FooBase like so:
public class FooBase
{
public FooA A;
public FooB B;
public byte[] Serialize()
{
var s = new RisMemoryStream();
// placeholders
var fatPtrAPosition = RisIO.Seek(s, 0, SeekFrom.Current);
RisIO.WriteFatPtr(s, new FatPtr());
var fatPtrBPosition = RisIO.Seek(s, 0, SeekFrom.Current);
RisIO.WriteFatPtr(s, new FatPtr());
// serialize
var bytesA = A.Serialize();
var fatPtrA = RisIO.Write(s, bytesA);
var bytesB = B.Serialize();
var fatPtrB = RisIO.Write(s, bytesB);
// go back to placeholders and write actual fatptrs
RisIO.Seek(s, fatPtrAPosition, SeekFrom.Begin);
RisIO.WriteFatPtr(s, fatPtrA);
RisIO.Seek(s, fatPtrBPosition, SeekFrom.Begin);
RisIO.WriteFatPtr(s, fatPtrB);
var result = s.ToArray();
return result;
}
public static FooBase Deserialize(byte[] value)
{
var result = new FooBase();
var s = new RisMemoryStream(value);
var fatPtrA = RisIO.ReadFatPtr(s);
var fatPtrB = RisIO.ReadFatPtr(s);
var bytesA = RisIO.ReadAt(s, fatPtrA);
var bytesB = RisIO.ReadAt(s, fatPtrB);
result.A = FooA.Deserialize(bytesA);
result.B = FooB.Deserialize(bytesB);
return result;
}
public static FooB DeserializeOnlyB(byte[] value)
{
var s = new RisMemoryStream(value);
RisIO.Seek(s, 8, SeekFrom.Current); // skip fatPtrA
var fatPtrB = RisIO.ReadFatPtr(s);
var bytesB = RisIO.ReadAt(s, fatPtrB);
var result = FooB.Deserialize(bytesB);
return result;
}
}
Now, the deserialize methods of FooA and FooB take a byte[] again. Because of that, FooA and FooB cannot do any out-of-bounds shenanigans.

Some more strategies
While we know enough now to serialize to our hearts desire, there are a few quality-of-life features that are very nice to have.
For example, we have a byte array, yes. But we would like to know what we are actually looking at, without deserializing the entire thing. Our binary format may be huge after all. If a user puts, idk, a PNG file into something that expects our custom format, it would be very nice to stop early before we are deserializing who knows what.
The easiest and most common solution to this problem is what's called a "magic value". A magic value consists of arbitrary bytes, which are written at the very beginning of our format. Thus, it's the first thing we can read.
For example, every PNG file starts with the bytes 137, 80, 78 and 71, which in escaped Unicode spells "\u0089PNG". As another example, every one of my assets in ris_engine starts with the ASCII "ris_".
To serialize, we simply write the magic bytes first and then serialize after. To deserialize, we read the magic bytes and compare if they are as expected. If not, return an error. If they are as expected, continue deserialization. They may be called magic values, but there is no black magic to be found here.

Another reason why a byte stream might not be as expected, is because of a version change. Maybe you are maintaining a program, which is in use for quite a while now and receives updates regularly. In that case the magic value of your format may stay the same, but you need to bump the version to prevent incompatible versions from breaking your program.
You can use different things for your version. A string is probably easiest, but the most wasteful. glTF for example uses a string to identify its version. You can also use an integer, or multiple if you are going the semver route. If you are clever, you can even put a MAJOR.MINOR.PATCH version in a single int, like how Vulkan is doing.
But we may be overthinking things. The version is comparably small in relation to the rest of any format 🤔
Another feature you may want is a header. A header consists of a number of bytes that are always there at the start of your format. The magic value and version is usually part of the header. But a header can hold additional information, for example the number of channels in an audio file or the dimensions of an image file.
Putting all these features into one code example, we might end up with something that looks like this:
public class MyCustomFormat
{
private static readonly byte[] ExpectedMagic = { 1, 2, 3, 4, 5 };
private const int ExpectedVersion = 42;
public byte[] Magic = ExpectedMagic;
public int Version = ExpectedVersion;
public string Meta = "some meta data";
public byte[] Serialize()
{
var s = new RisMemoryStream();
RisIO.Write(s, Magic);
RisIO.WriteInt(s, Version);
RisIO.WriteString(s, Meta);
// ...
return s.ToArray();
}
public static MyCustomFormat Deserialize(byte[] value)
{
var s = new RisMemoryStream(value);
// magic
var magic = RisIO.Read(s, ExpectedMagic.Length);
for (var i = 0; i < ExpectedMagic.Length; ++i)
{
var left = ExpectedMagic[i];
var right = magic[i];
if (left != right)
{
throw new FormatException("magic does not match");
}
}
// version
var version = RisIO.ReadInt(s);
if (version != ExpectedVersion)
{
throw new FormatException("version does not match");
}
// meta
var meta = RisIO.ReadString(s);
// deserialize the rest
var result = new MyCustomFormat();
result.Magic = magic;
result.Version = version;
result.Meta = meta;
// ...
return result;
}
}
A header may be of any type and can contain as many fields as you want. To keep the example short and simple, I chose to use a single string as meta data.
At last, but not least, you might want to be backwards and forwards compatible between different versions. This is a beast of a problem, especially when multiple people over multiple generations are maintaining such a format. Infamously, the .docx file format from Microsoft Word solved this by simply using a zipped XML container. If you have a .docx file lying around, you can literally unzip it. You will get a directory structure, which you can easily view with any file explorer.

I have yet to implement such a format in binary, but I did something like it in XML though. So I have no experience on how you would develop such a format in binary. But I can tell you what I would try!
I would heavily rely on chunks. By which I mean: FatPtrs everywhere. At the start of each chunk, an enum or its "kind" is stored, which determines what exactly this chunk is doing. If a deserializer reads a kind of chunk that it does not recognize, the chunk is ignored. If you are not using FatPtrs, store them right after each other. Each chunk would then also store its size, such that a deserializer, who doesn't recognize a chunk, can skip it.
Compression and encryption
As I've hinted in the chapter about bools, our implementation is quite naive and simplistic, which wastes quite a bit of space. We can try to decrease the size of our data by compressing it. But I have to mention that not all data compresses equally. Some data is resistant to compression. Also, you may be interested in encryption, because you might store sensitive data.
Well, compression and encryption are two entirely different disciplines. Explaining each one in detail is waaaayy beyond the scope of this post. Either one is a rabbit hole on its own. For our use case, only this counts: Both compression and encryption are methods, which take a byte array and spit out a new byte array. Compression will reduce the amount of bytes, and encryption will scramble the bytes.
Since we deserialize into a byte array, compressing and encrypting is as easy as calling the according method on our byte array.
public class MySmallAndEncryptedData
{
private static byte[] Compress(byte[] value)
{
// ...
}
private static byte[] Decompress(byte[] value)
{
// ...
}
private static byte[] Encrypt(byte[] value)
{
// ...
}
private static byte[] Decrypt(byte[] value)
{
// ...
}
public byte[] Serialize()
{
var s = new RisMemoryStream();
//...
var bytes = s.ToArray();
var compressed = Compress(bytes);
var encrypted = Encrypt(compressed);
return encrypted;
}
public static MySmallAndEncryptedData Deserialize(byte[] value)
{
var decrypted = Decrypt(value);
var decompressed = Decompress(decrypted);
var s = new RisMemoryStream(decompressed);
var result = new MySmallAndEncryptedData();
// ...
return result;
}
}
And that's all there is to it. There are many different compression and encryption algorithms out there, many of which have dedicated libraries. You can pick and choose whatever you want. The sky is the limit.
Usually, you don't want to compress or encrypt the entire format. Usually, you want to keep the magic value, version and sometimes even the entire header readable. The reason is simple: You want the receiver to be able to identify what they are looking at, and that will be difficult when the data is mangled.
To take ris_engine again as an example, all my internal formats have a 16-byte magic value at the start of each asset. Each one starts with "ris_" to identify them as one of my assets. The remaining 12 characters indicate what kind of asset one is looking at. Below is a screenshot of my "ris_scene" format. By the mangled nature of the bytes, one can guess that it was compressed. But the "ris_scene" at the start remains readable.

If you want to learn more about compression and encryption, I leave you with these Wikipedia articles:
Conclusion
Wow, what a journey. It took some work, but now you should have everything that you need to build your own binary format. I am sure I have written something that you disagree with, and that is fine. Now, you have the knowledge to make adjustments to my code and implement what you actually need or want. And with these tools under your belt, it shouldn't be too difficult to cook up your own binary format.
I claimed in the intro that a custom binary format is easily smaller and faster than JSON. So I will leave you with a benchmark. It compares my serializer with an equivalent implementation using Json.NET by Newtonsoft, a popular JSON library for C#. The benchmark results are below.
(lower is better)


I hope it is evident that a custom serializer easily outperforms a general one.
A complete implementation of the code in this post, including this benchmark, can be found here: LINK
|

| ◀ | Previous Post: Rust is the future |
| ▶ | More Programming related Posts |