
Building a JobSystem
Programming · Oct 6th, 2022
If the hero were the phrase "premature optimization is the root of all evil", then I'd be its villain. I might be an uninteresting and boring villain, but its villain nonetheless.
Anyway, there is one idea that really caught me on fire, ever since I first came across it. Pretty much most game engines that you will come across, as well as any tutorials that may claim to teach you how to program one, they all hinge on the same basic, single threaded main loop.
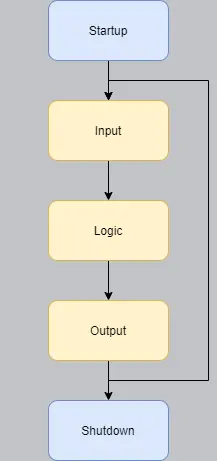
This is fine, until you realize that today's machines have multiple processors. If the entire engine runs only on one thread, then no matter how many cores your processor has, only the speed of one actually determines how fast your game is running.
Naïve me, and multiple people that I've seen online, all seem to come to the same idea eventually: Simply divide the engine into different threads! For example, have one thread that runs the input and logic, and have another thread that runs the output. But this is not an ideal solution. One job will be more expensive than the other. Either the logic, or the output (most definitely the rendering) will take a larger amount of time to compute. So to have things synced up properly, one must wait for the other, wasting CPU cycles. To solve this, maybe you think you simply have to divide the engine into even more threads. But this becomes very complicated very quickly, with diminishing returns.
No. What I want is what Jason Gregory proposes in his book "Game Engine Architecture": A Job System.
The idea doesn't sound so difficult at the first glance: You spawn a thread for every available core. You have a queue where you can push jobs to. The worker threads then constantly try to dequeue jobs from it, and run them. A job is simply a piece of code, usually a pointer to a function. The potential of this idea is huge: In the best case, it gives you access to 100% of the CPU 100% of the time. Sure, we need additional job system logic, which overall is more work. But since we can do multiple things at once, this overhead is definitely worth the effort, and reduces the computation time in total.
Thread Pool Theory
One of the best books about programming I've ever read, is "C++ Concurrency in Action" by Anthony Williams. Even though I made the switch to Rust a few months ago, the book was still immensely helpful for understanding and designing multithreaded stuff. And the job system that I've implemented is inspired by the thread pool that Anthony proposed in his book. So before we dig into my spaghetti code, it's probably a good idea to first understand how a thread pool works. By that I mean, we'll go and look at Anthony's thread pool.
Naïve Thread Pool
In the most naïve way possible, a thread pool is fairly easy to implement: Have one concurrent queue and share it among every worker thread.
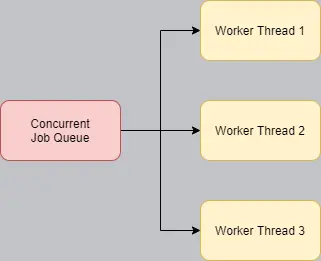
This is primitive, but it should work. Nonetheless, this design has a huge problem: Congestion. This naïve solution has multiple threads that are all constantly trying to dequeue jobs from the job queue. This means that the queue must be absolutely thread safe. This begs the question, how does something become thread safe? Simply put, it prevents simultaneous accesses from different threads. There are various techniques to accomplish this. There exist blocking and non-blocking methods, but ultimately, a thread safe object turns multithreaded accesses into "single threaded" ones. (My explanation isn't quite correct, concurrent accesses on a thread safe object still happen on different threads. But since all accesses happen in order and never at the same time, they may as well be single threaded. You get my point.) This is a huge huge problem, because we wanted a system that could run things in parallel, and now this queue alone is preventing that entirely.
To fix this, we somehow need to avoid threads attempting to access the same data. Luckily, I don't have to be smart to figure this one out, and Anthony proposes a better solution.
Local Job Buffers
The key thing to realize, is that jobs can submit other jobs. Jobception. If we enqueue these to the shared job queue, we have an even bigger congestion problem. No. Instead, each worker thread has its own job queue, where it can submit and dequeue jobs.
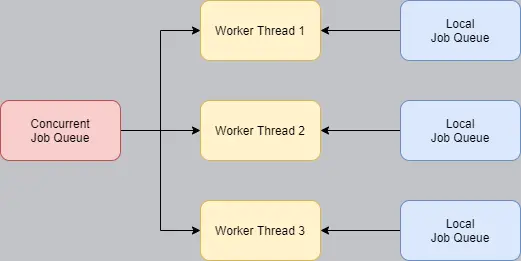
Now, a worker thread only attempts to dequeue from the global job queue, if its own local queue is empty. Also notice that only the worker thread has access to its queue, so the queue doesn't even need to be thread safe!
This is a much better solution, but it is still prone to problems. Imagine again that we have a logic job and an output job, that are both submitted to this job system. One worker may receive the logic job, and another receives the output job. Since jobs can push other jobs, and these are enqueued to the local buffer, logic jobs will always stay on thread A, while render jobs will always stay on thread B. But just like before, one job is much more expensive than the other one. And even though we have enough jobs for everyone, because they never leave their worker thread, we get this situation again:
Anthony comes to the rescue one more time!
Stealing Jobs
The final design proposes that every worker thread actually has a reference to the local queues of the other threads, such that workers may steal jobs from each other.
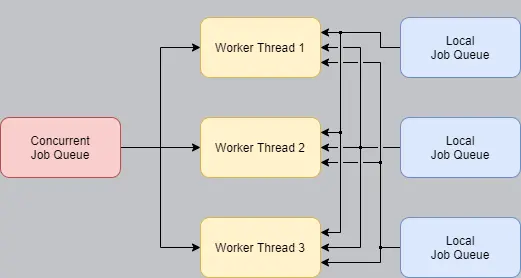
This implies that the local job queues must be thread safe again. Also, we stop talking about queues, and more about buffers. More precisely, a deque. If the container that holds the jobs where a simple queue, we would run into the congestion problem again. But to allow for maximum parallel work, jobs are pushed and popped from the same end of the buffer, while stealing is done from the opposite end. This ensures that even though multiple threads access the same buffer, they happen at different locations on the buffer, so stealing and popping can happen simultaneously. The only way we could run into congestion, is if the buffer were empty. But in this edge case we simply don't care, because what is a worker thread going to do if it is empty? Wait? Since there isn't anything to do anyway, we can absolutely afford to congest.

While a bit more complicated, this solution is much more sophisticated. Full credit to Anthony. And it is this thread pool, which I decided to build upon.
My Job System
Now that we have a basic understanding of how a sophisticated job system looks like, let me present you my altered version. In total, my system is built from 5 parts, which we will tackle in order:
- Job. Simple wrapper around a function pointer. Until I figure out how to store function pointers in a collection, a wrapper is required.
- JobBuffer. Buffer that holds Jobs. It isn't really a queue, neither is it really a deque, it's more akin to a weird stack, but at the same time it isn't. It's specially designed for this job system, and isn't even thread safe if used incorrectly, but we'll talk about it later.
- JobSystem. Collection of globally available functions, to setup worker threads, submit jobs and run pending jobs.
- JobFuture. Utility to wait and return values from jobs.
- JobCell. Utility, to pass references into a job. Rusts ownership rules made this absolutely necessary and a real headache to design.
Without further ado, let's jump into some Rust code 😊
Job
As stated above, I honestly don't know how to store function pointers in a container elegantly. In Rust, every function is unique. Even if two functions were to have the same signature, they are still considered different from each other. Thus, such two similar functions cannot be stored in the same collection, unless you put them into some sort of wrapper. To make my life easier, I simply created a wrapper that stores a single function pointer. Since every Job is syntactically the same, they can be effortlessly stored in a container.
pub struct Job {
to_invoke: Option<Box<dyn FnOnce()>>,
}
impl Job {
pub fn new<F: FnOnce() + 'static>(to_invoke: F) -> Self {
let to_invoke: Option<Box<dyn FnOnce()>> = Some(Box::new(to_invoke));
Self { to_invoke }
}
pub fn invoke(&mut self) {
if let Some(to_invoke) = self.to_invoke.take() {
to_invoke();
}
}
}
impl std::fmt::Debug for Job {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
let result = match self.to_invoke {
Some(_) => "Some",
None => "None",
};
write!(f, "{{ to_invoke: {} }}", result)
}
}
To be able to invoke the function pointer, it is stored in an Option, such that when calling it, we can take ownership of it. It should go without saying, that this Job can only be invoked once, because once we moved the function pointer out of Option, there is no function pointer left.
JobBuffer
There is one thing that you must know, when designing interfaces for thread safe constructs: The more flexible the public interface, the more race conditions you introduce. While impractical, assume the following example: A worker thread only wants to pop jobs of the buffer, if they are for example render jobs. To program something like this, you would have a peak method, that checks the next job without popping it off the buffer. The caller then can check the job. If it's the right kind, pop it. Client code would look something like this:
let job = job_system::peak();
if job.kind == JobKind::Render {
let mut render_job = job_system::pop();
render_job.invoke();
}
This code would be fine in a single threaded context, but this introduces a race condition. Between job_system::peak() and job_system::pop(), another thread may pop off a job. Thus, even though the if-statement may be true, a different job is popped off than what was peaked at. This means, render_job may actually not be a render job.
The simple solution is to keep your interface to an absolute minimum. Besides its constructor, my job buffer only exposes 3 methods: Push, pop and steal. Peaking and indexing are not implemented, because they cause race conditions and aren't used by my system.
An iterator may be helpful, but iterators are notoriously difficult to make thread safe. Whatever mechanism you use to prevent other threads to access your collection, it somehow must live at least as long as the iterator. This introduces many difficult questions, like who owns the locking mechanism, or how to sync it with the iterator? It's probably best to just not implement it.
is_empty() may be useful, and I even have the use case for it, but ultimately it's redundant. Because steal() and pop() can simply return None when no job exists, is_empty() provides truly redundant information.
count or length are also useless: Either there are jobs in the buffer that can be popped off, or there are none. There will never be a case, where I would want to know how many jobs are currently stored in the buffer.
It should become a bit clearer now, why I am calling it a buffer, and not queue, deque or stack. It is lacking seriously in features. Also, it isn't technically a queue, nor stack, because jobs can be popped from both sides. It isn't a deque either, because it can push only from one side.
Okay, that were a lot of preambles, but how to actually build such a thing? Hang in there, we gotta talk collections first. We will see code soon enough.
I was quite surprised how many different designs there are. I went through at least 10 different prototypes before I landed on the buffer that I am currently using. Initially, I wanted to write a doubly linked list. Those come with a hefty number of drawbacks and they are stupidly difficult to write in Rust. But I wanted one, because it can hold infinite items in theory. When a buffer is full, and a job is pushed, what should happen? For a long time, I didn't want to answer this question, hence I was only considering a buffer with theoretical infinite size.
But eventually, while going for a walk, I realized something: When a buffer is full, I can simply invoke the job. The caller shouldn't care whether the submit function blocks or not. All that matters is that the job system is making progress somehow. If the caller needs to be interrupted to invoke another job, then this is totally fine. Even though the caller may not make progress, another job will be, therefore no resources are wasted.

My choice to implement the JobBuffer fell onto the ring buffer. A ring buffer is just an array or vector, with one or two cursors, keeping track where the current head and tail are. It's called a ring buffer, because the cursors wrap around the array, thus it effectively has no start and end, like a ring. Once allocated, no further allocations are necessary to use it. Also, no nasty pointer issues arise. And to top it all off, a ring buffer can be entirely coded in safe Rust, which is always a big bonus.
To familiarize yourself with it, here's a simple playground I've built in JavaScript, where you can familiarize yourself with the concept:
We're finally done with the preamble, let's jump into code:
pub struct JobBuffer {
head: UnsafeCell<usize>,
tail: Mutex<usize>,
jobs: Vec<Mutex<Option<Job>>,
}
This is the entire struct. it stores the current head and tail, as well as a vector of jobs.
This definition may confuse you. Why is the head an UnsafeCell<usize>? Why not a Mutex<usize>, like the tail? Why does the job vector also store mutexes? Isn't locking the head and tail safe enough?
Pushing and popping will happen on the head. Stealing will happen on the tail. I hope it should be fairly obvious why the tail needs to be a mutex. Multiple worker threads may steal from the same buffer. As such, the tail needs to be protected. Okay, but doesn't this also apply to the head? Well, no. Notice that only the worker thread that owns the buffer is pushing and popping jobs. Because a single thread is calling push and pop, there will never ever be the case, that push() or pop() will be called simultaneously. This means, as an optimization, we can simply leave the head unprotected. This is what I meant earlier, that this buffer isn't thread-safe, if you use it incorrectly. But since we aren't using it incorrectly, we are perfectly safe and sound.
Okay, but why do the items in the vector need to be protected? Doesn't that mean that we have to lock 2 mutexes to access a single entry? Yes, and that's one downside of this design. But till now, this didn't cause too much performance issues, so I am not worrying about it yet. While I can't get rid of this extra mutex, you should still understand why it is needed: When the buffer is full or empty, the tail and the head point to the same node, and thus two different threads may access the same node simultaneously. This needs to be prevented. We can't lock both head and tail, because that would mean if one thread were to call steal(), a second thread cannot call pop(). We want that 2 threads can work on the same buffer at the same time. Thus, the node itself must be stored within a mutex.
impl JobBuffer {
pub fn new(capacity: usize) -> Arc<Self> {
let mut jobs = Vec::with_capacity(capacity);
for _ in 0..capacity {
jobs.push(Mutex::new(None));
}
Arc::new(Self {
head: UnsafeCell::new(0),
tail: Mutex::new(0),
jobs,
})
}
}
The constructor should now be very straightforward. We create a vector with a fixed capacity, and insert empty nodes. Notice that we return an Arc<Self>. This makes the client code a bit tidier, because this buffer is never used on its own, it will always be duplicated somehow.
impl JobBuffer {
pub fn push(&self, job: Job) -> Result<(), BlockedOrFull> {
let head = unsafe { &mut *self.head.get() };
let mut node = match self.jobs[*head].try_lock() {
Ok(node) => node,
Err(std::sync::TryLockError::WouldBlock) => {
return Err(BlockedOrFull { not_pushed: job })
}
Err(std::sync::TryLockError::Poisoned(e)) => throw!("mutex is poisoned: {}", e),
};
match *node {
Some(_) => Err(BlockedOrFull { not_pushed: job }),
None {
*node = Some(job);
*head = (*head + 1) % self.jobs.capacity();
Ok(())
}
}
}
}
Push is a bit more complicated. Notice the unsafe block in the first line of this method. As I've explained earlier, this doesn't cause problems, because this will only ever be accessed by a single thread. We then lock the node at the current head. Notice how this is a try_lock, not a lock. This avoids blocking, meaning the job system can progress, even if the push failed. If we managed to lock the node, we can then see if there is a job inside or not. If there is a job already, the buffer is full. If there is no job, then we can overwrite it and update the head.
Note that the BlockedOrFull error takes ownership of the job. This allows the not-pushed job to be returned to the caller, so that they may invoke it.
impl JobBuffer {
pub fn wait_and_pop(&self) -> Result<Job, IsEmpty> {
let head = unsafe { &mut *self.head.get() };
let new_head = if *head == 0 {
self.jobs.capacity() - 1
} else {
*head - 1
};
let mut node = unwrap_or_throw!(self.jobs[new_head].lock(), "mutex is poisoned");
match node.take() {
None => Err(IsEmpty),
Some(job) => {
*head = new_head;
Ok(job)
}
}
}
}
Pop is very similar, but the new head is computed first and then the node is locked. Note that it uses lock, not try_lock. A worker thread attempting to pop a job literally has nothing else to do. So to make progress, the best option is to block until we can access the node. Then, whether or not there is a job, we return the job or an IsEmpty error.
impl JobBuffer {
pub fn steal(&self) -> Result<Job, BlockedOrEmpty> {
let mut tail = self.tail.try_lock().map_err(to_steal_error)?;
let old_tail = *tail;
let mut node = self.jobs[old_tail].try_lock().map_err(to_steal_error)?;
match node.take() {
None => Err(BlockedOrEmpty),
Some(job) => {
*tail = (old_tail + 1) % self.jobs.capacity();
Ok(job)
}
}
}
}
Again, steal is very similar. But unlike the head in push and pop, the tail needs to be locked, because it is protected by a mutex. Notice how this one is using a try_lock and not a lock. This is due to there being number of CPUS - 1 amount of buffers to steal from. If we can't steal from this buffer, we simply steal from the next one. There is no need to block. After that, we then lock the node. If we were successful, we compute the next tail and return the job, otherwise we return an error.
At last, but not least, we need some utility stuff, so that this buffer compiles and can actually be shared between threads:
unsafe impl Send for JobBuffer {}
unsafe impl Sync for JobBuffer {}
fn to_steal_error<T>(error: TryLockError<T>) -> BlockedOrEmpty {
match error {
std::sync::TryLockError::WouldBlock => BlockedOrEmpty,
std::sync::TryLockError::Poisoned(e) => throw!("mutex is poisoned: {}", e),
}
}
And there we have it. A highly specialized buffer to store jobs.
This JobBuffer is about 100 lines of code, but to test it I wrote 1180 lines! (including whitespaces)
This buffer is the core of my job system, which is the core of my game engine. So it must be water tight. I really can't afford this buffer to blow up, under any circumstance. As such, Anthony Williams recommended himself, to write as much tests as possible, to test every thinkable edge case, no matter how rare. What if one thread is pushing while another is stealing? What if 100 threads are stealing on an empty buffer? What if 1 thread is popping from an empty buffer? What if one thread is pushing and popping on a full buffer, while 100 threads are stealing?
But the painful, repetitive work was absolutely worth it. To this day, I haven't encountered a single issue with the JobBuffer, and it's been 530 days, since its implementation. And I am quite confident that it does its job properly. Maybe I will encounter a bug in the future, but I seriously don't think I will encounter a serious problem, ever.
Narrator: The moment the buffer blows up, he will regret to have said this.
EDIT 17th March, 2024. The system did, in fact, blow up:
https://www.rismosch.com/article?id=i-found-a-bug-in-my-job-system
JobSystem
You may or may not have figured out, that the JobBuffer described in the previous section is the local JobBuffer, which is owned by a worker thread. What about the globally shared JobBuffer? For better or for worse, I got rid of it.
Anthony Williams' thread pool seems fine, but I was always asking myself: Who is pushing onto the global buffer? I feel like Anthony's thread pool is designed for a general purpose. It most likely finds use in some enterprise project. Maybe a user is requesting a search or find feature, and then the program would initiate a thread pool to do just that. Maybe there will be additional threads that also push onto the thread-pool. Nonetheless, I really want to do what Naughty Dog did with their engine: Jobify the entire thing. EVERYTHING will run on this job system, with a few significant exceptions: Startup, shutdown, logging and IO. Everything that runs on the job system will push local jobs.
I also thought about who would own the main game loop. This too went through many different design iterations, but I realized soon enough that the main thread can also be a worker thread. The main thread can own a local JobBuffer too, and it would execute a "GodJob", that lives for the entirety of the program. When the god job ends, it waits for all currently enqueued jobs. After all workers have been ended, the engine is allowed to shut down.
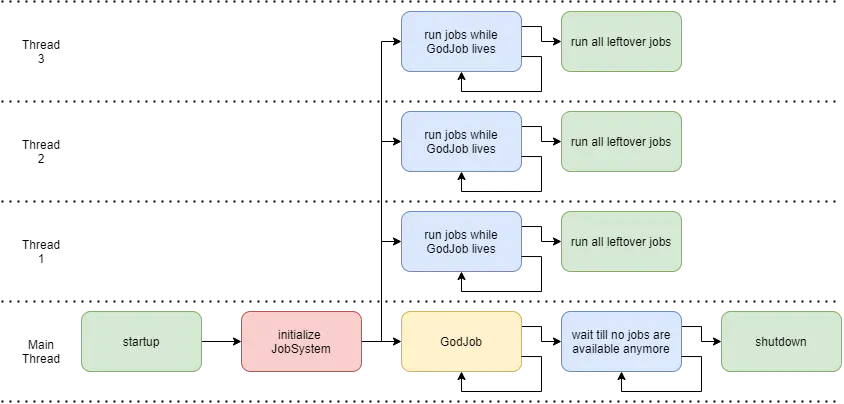
Let's start with some structs:
thread_local! {
static WORKER_THREAD: RefCell<Option<WorkerThread>> = RefCell::new(None);
}
struct WorkerThread {
local_buffer: Arc<JobBuffer>,
steal_buffers: Vec<Arc<JobBuffer>>,
index: usize,
}
pub struct JobSystemGuard {
handles: Option<Vec<JoinHandle<()>>>,
done: Arc<AtomicBool>,
}
First, we have a thread local variable. It stores an Option, because a thread that wasn't initialized as a worker thread cannot serve as a worker thread.
The WorkerThread currently stores 3 things: The JobBuffer that it owns, the JobBuffers from the other workers, and an index, that uniquely identifies this thread. The index is mainly used for debug purposes, and it's a utility that directly comes with my job system. As such, the index isn't linked to the platform, the OS, or anything of that nature.
JobSystemGuard is the struct that will be returned when the job system is initialized. If this guard is dropped, the job system will be shut down. Due to its singleton-like behavior, it didn't feel right to have a struct that represents the job system, similar of how you would design an OOP singleton. Instead, it gives the caller the opportunity to drop it at a specified time. The JobSystemGuard stores all handles of every spawned worker thread, and an AtomicBool to signal when worker threads should be shut down.
pub fn init(buffer_capacity: usize, threads: usize) -> JobSystemGuard {
// estimate workthreads and according affinities
let cpu_count = cpu_info().cpu_count as usize;
let threads = std::cmp::min(cpu_count, threads);
let mut affinities = Vec::new();
for _ in 0..threads {
affinities.push(Vec::new());
}
for i in 0..cpu_count {
affinities[i % threads].push(i);
}
// setup job buffers
let mut buffers = Vec::with_capacity(threads);
for _ in 0..threads {
buffers.push(JobBuffer::new(buffer_capacity))
}
let done = Arc::new(AtomicBool::new(false));
// setup worker threads
let mut handles = Vec::with_capacity(threads - 1);
for (i, core_ids) in affinities.iter().enumerate().take(threads).skip(1) {
let core_ids = core_ids.clone();
let buffers = duplicate_buffers(&buffers);
let done_copy = done.clone();
handles.push(thread::spawn(move || {
setup_worker_thread(&core_ids, buffers, i);
run_worker_thread(i, done_copy);
}))
}
ris_log::debug!("spawned {} additional worker threads", handles.len());
let handles = Some(handles);
// setup main worker thread (this thread)
let core_ids = affinities[0].clone();
let buffers = duplicate_buffers(&buffers);
setup_worker_thread(&core_ids, buffers, 0);
JobSystemGuard { handles, done }
}
The init method may look daunting at first, but it's actually very straight forward. It takes 2 values: The size of the JobBuffers and how many threads should be spawned. First, we clamp the threads to the number of processors that your machine has. This is to prevent spawning more threads than cores.
Then we calculate the affinities. Affinity allows you to lock a thread only to a specific core. For example, if a thread has affinity 0, 1 and 2, then it will run only on core 0, 1 and 2. Every worker thread should run on a different core, otherwise worker threads can interrupt each other, which may result in a performance loss.
Assume your PC has 12 cores. If you were to spawn 5 worker threads, my code would estimate the affinities like so:
| Thread | Affinity |
| 0 | 0, 5, 10 |
| 1 | 1, 6, 11 |
| 2 | 2, 7 |
| 3 | 3, 8 |
| 4 | 4, 9 |
After we've calculated the affinities, we simply create one JobBuffer for every worker thread. We also create the done flag.
Since the main thread is also a worker thread, we will be spawning threads - 1 number of workers. For each we clone the affinities, the buffers and the done flag. Once spawned, each thread will first set itself up and then run itself.
Just right after that, the main thread is doing the same, but it also collects the handles and puts them into the JobSystemGuard. The job system is now setup and already running!
Now let's see how it's dropped:
impl Drop for JobSystemGuard {
fn drop(&mut self) {
ris_log::debug!("dropping job system...");
self.done.store(true, Ordering::SeqCst);
empty_buffer(0);
match self.handles.take() {
Some(handles) => {
let mut i = 0;
for handle in handles {
i += 1;
match handle.join() {
Ok(()) => ris_log::trace!("joined thread {}", i),
Err(_) => ris_log::fatal!("failed to join thread {}", i),
}
}
}
None => ris_log::debug!("handles already joined"),
}
ris_log::debug!("job system finished")
}
}
First, we set the done flag to true, so every worker thread knows it's time to stop. The main thread then empties its local buffer, meaning it is popping all jobs left in the buffer and running them. Then we take the handles, and join each worker thread. With some logging thrown in, that's all that drop does.
Let's take a look at all the utility functions, that the previous two code snippets were using:
fn duplicate_buffers(buffers: &Vec<Arc<JobBuffer>>) -> Vec<Arc<JobBuffer>> {
let mut result = Vec::new();
for buffer in buffers {
result.push(buffer.clone());
}
result
}
This method duplicates the array of JobBuffers, thus every worker thread can have a copy of all available buffers.
fn setup_worker_thread(core_ids: &[usize], buffers: Vec<Arc<JobBuffer>>, index: usize) {
match ris_os::affinity::set_affinity(core_ids) {
Ok(()) => ris_log::trace!("set affinity {:?} for thread {}", core_ids, index),
Err(error) => ris_log::error!("couldn't set affinity for thread {}: {}", index, error),
};
let local_buffer = buffers[index].clone();
let mut steal_buffers = Vec::new();
for buffer in buffers.iter().skip(index + 1) {
steal_buffers.push(buffer.clone());
}
for buffer in buffers.iter().take(index) {
steal_buffers.push(buffer.clone());
}
WORKER_THREAD.with(move |worker_thread| {
*worker_thread.borrow_mut() = Some(WorkerThread {
local_buffer,
steal_buffers,
index,
});
});
}
Setting up a worker thread is a bit more involved. First, we set the affinity. This is simply a wrapper around the Windows API, nothing special.
Then, we choose our local buffer. This is simply the buffer at the worker threads index. Meaning, the local buffer of thread 0 will be at index 0. The local buffer of thread 42 will be at index 42.
Using 2 for loops, we then get the buffers from which will be stolen from. We start at index + 1 and then wrap around. This diagram illustrates how the buffers will be arranged, for worker thread 2 on a machine with 5 cores:

After the busy work, we then simply set the thread-local variable with the necessary information.
fn run_worker_thread (index: usize, done: Arc<AtomicBool>) {
while !done.load(Ordering::SeqCst) {
run_pending_job();
}
empty_buffer(index);
}
Running the worker thread is very straight forward. While the done flag is false, we are stuck in an endless loop, running jobs that are still waiting to be executed. If the done flag is true, we empty the buffer, like the main thread does when JobSystemGuard is dropped.
pub fn run_pending_job() {
match pop_job() {
Ok(mut job) => job.invoke(),
Err(IsEmpty) => match steal_job() {
Ok(mut job) => job.invoke(),
Err(BlockedOrEmpty) => thread::yield_now(),
},
}
}
To run a pending job, we first pop from our local buffer. If it is successful, we invoke it. If our local buffer is empty, we steal from the other buffers instead. If this is successful, we just stole a job and can invoke it. If no job was popped or stolen, we yield, to give room for other threads.
run_pending_job() is public, because as you will see in the sections JobFuture and JobCell, it is quite useful to let others run jobs as well.
fn empty_buffer(index: usize) {
loop {
ris_log::trace!("emptying {}", index);
match pop_job() {
Ok(mut job) => job.invoke(),
Err(IsEmpty) => break,
}
}
}
Emptying the local buffer is also very straight forward. We are stuck in a loop, popping jobs from our local buffer and running them, until it's empty.
Now we've seen several functions that pop and steal jobs. So now it's time to show what these functions are doing in detail:
fn pop_job() -> Result<Job, IsEmpty> {
let mut result = Err(IsEmpty);
WORKER_THREAD.with(|worker_thread| {
if let Some(worker_thread) = worker_thread.borrow_mut().as_mut() {
result = worker_thread.local_buffer.wait_and_pop();
} else {
ris_log::error!("couldn't pop job, calling thread isn't a worker thread");
}
});
result
}
Popping literally does nothing except calling wait_and_pop() of its local buffer. If for whatever reason this method is called from a non-worker thread, then this method returns nothing and prints an error instead.
fn steal_job() -> Result<Job, BlockedOrEmpty> {
let mut result = Err(BlockedOrEmpty);
WORKER_THREAD.with(|worker_thread| {
if let Some(worker_thread) = worker_thread.borrow_mut().as_mut() {
for buffer in &worker_thread.steal_buffers<> {
result = buffer.steal();
if result.is_ok() {
break;
}
}
} else {
ris_log::error!("couldn't steal job, calling thread isn't a worker thread");
}
});
result
}
Stealing is pretty much the same, except that because we have a vector of buffers, we iterate through them. The first steal that succeeds breaks the iteration. Just like pop_job(), if this is called from a non-worker thread somehow, this method will print an error.
With all the setting up, tearing down and dequeuing taken care of, let's look at the thread index:
pub fn thread_index() -> i32 {
let mut result = -1;
WORKER_THREAD.with(|worker_thread| {
if let Some(worker_thread) = worker_thread.borrow().as_ref() {
result = worker_thread.index as i32;
} else {
ris_log::error!("calling thread isn't a worker thread");
}
});
result
}
This simply returns the thread-local index. If the calling thread is not a worker thread, -1 is returned and an error is printed.
I reserved the submit function for last, because it uses JobFutures, which I'll explain in the next section. But here it finally is:
pub fn submit<ReturnType: 'static, F: FnOnce() -> ReturnType + 'static>(
job: F,
) -> JobFuture<ReturnType> {
let mut not_pushed = None;
let (settable_future, future) = SettableJobFuture::new();
let job = Job::new(move || {
let result = job();
settable_future.set(result);
});
WORKER_THREAD.with(|worker_thread| {
if let Some(worker_thread) = worker_thread.borrow_mut().as_mut() {
match worker_thread.local_buffer.push(job) {
Ok(()) => (),
Err(blocked_or_full) => {
not_pushed = Some(blocked_or_full.not_pushed);
}
}
} else {
ris_log::error!("couldn't submit job, calling thread isn't a worker thread");
}
});
if let Some(mut to_invoke) = not_pushed {
to_invoke.invoke();
}
future
}
This function takes a closure, that can return a value. This is the job to be run. And it returns a JobFuture, which can return the jobs returned value. You may remember, that Job was a very very simple wrapper around a function pointer, which doesn't even return anything. That is intentional, to make my life easier. Instead of handing the closure directly into the job, and thus forcing me to somehow accommodate for its return value, it's much easier to simply wrap the closure into another closure, that doesn't return anything.
submit() first creates the future. This includes a SettableJobFuture and a JobFuture. Soon you will see, that they share a mutex, but the split between "settable" and "non-settable" prevents client code to set the future themselves.
Then it creates said closure, which sets the future with its return value. After that, we simply call push() from our thread-local local buffer. Recall that pushing returns the job, when the buffer is full. In that case, we store it in not_pushed and invoke it later. At the very end, we return the non-settable JobFuture, so that the client may wait on the job that was just submitted.
If you read this far, and understood everything, I have to commemorate you. To come to this point, I've read several books already. Even though this blogpost is already incredibly long, it still condenses a lot of information, and I seriously applaud you if you could follow along with everything. But we aren't done yet, there are still 2 things that we need to talk about.
JobFuture
Submitting a job is an asynchronous operation. Submitting takes O(1) time, but the job itself will be executed on any core in some arbitrary point in the future. But what if you need to wait for the job to continue? For example, my Input system runs mouse, keyboard and gamepad in parallel, but my remapping system requires that these 3 systems are already computed. So before any remapping can take place, the input job needs to wait for the 3 children.
This is what the JobFuture is for. It gives client code a handle, which can be awaited. As you've already seen, it is split into a SettableJobFuture and a non-settable JobFuture. Let's just jump straight into it!
struct Inner<T> {
is_ready: bool,
data: Option<T>,
}
type InnerPtr<T> = Arc<Mutex<Inner<T>>>;
pub struct SettableJobFuture<T> {
inner: InnerPtr<T>,
}
pub struct JobFuture<T> {
inner: InnerPtr<T>,
}
Inner is simply the data to be stored. It stores a bool is_ready, which indicates whether the job is finished or not. data is the value, which was returned by the job. It is stored inside an Option, because sooner or later we need to move the data out. The Future can be in these 4 states:
| is_ready | data | state |
| false | None | Job is not done |
| true | Some | Job is done |
| true | None | Job is done, and data was moved out |
| false | Some | close eyes, cover ears and run screaming in circles |
SettableJobFuture and JobFuture literally store the same: An Arc<Mutex<Inner<T>>>. Thus, they are virtually identical. Because they are different structs however, they can implement different methods. For example, only SettableJobFuture has a constructor, and it returns both a SettableJobFuture and a JobFuture. Also, only SettableJobFuture can set its value. JobFuture can wait on a value, but SettableJobFuture cannot. Let's see:
impl<T> SettableJobFuture<T> {
pub fn new() -> (SettableJobFuture<T>, JobFuture<T>) {
let inner = Arc::new(Mutex::new(Inner {
is_ready: false,
data: None,
}));
let settable_job_future = SettableJobFuture {
inner: inner.clone(),
};
let job_future = JobFuture { inner };
(settable_job_future, job_future)
}
pub fn set(self, result: T) {
let mut inner = unwrap_or_throw!(self.inner.lock(), "couldn't set job future");
inner.is_ready = true;
inner.data = Some(result);
}
}
SettableJobFuture is very straight forward. It initializes the Arc<Mutex<Inner<T>>> which will be shared between the two structs. It then creates each struct and returns them. set() simply locks the mutex, sets is_ready to true, and overwrites data. Notice how set() consumes self. This directly means that once SettableJobFuture is changed, it might as well be dead.
Let's look at the await-able JobFuture next:
impl<T> JobFuture<T> {
pub fn wait(mut self) -> T {
match self.wait_and_take() {
Some(value) => value,
None => unreachable!(),
}
}
fn wait_and_take(&mut self) -> Option<T> {
loop {
match self.inner.try_lock() {
Ok(mut inner) => {
if inner.is_ready {
return inner.data.take();
}
}
Err(e) => {
if let TryLockError::Poisoned(e) = e {
throw!("couldn't take job future: {}", e);
}
}
}
job_system::run_pending_job();
}
}
}
Just like set() in SettableJobFuture, wait() also consumes self. This results in the fact, that taking data will always succeed. We can't wait() a second time, when it was awaited already. This is why the None branch of wait() includes an unreachable!() and why wait() can afford to return the value directly, instead of returning an Option.
wait() calls wait_and_take(), which spinlocks until data is set. Considering the reactions I got from a previous blogpost, people somehow seem to hate spinlocks and immediately consider them unsafe. But let me assure you, that without a spinlock, this future wouldn't work.
Assume for a second, that wait() uses a locking mechanism, like a condition variable or a mutex. In that case, waiting for the future would block the entire thread. This is problematic, because a blocked worker thread cannot run jobs. Ideally, the worker thread would do other things while the calling job is waiting. As such, a spinlock-like construct is the best choice for implementing such behavior.
This is what wait_and_take() does: It first calls try_lock() on the mutex, which isn't a blocking operation. If the lock was successful and the future was set, we can take the data inside. If the lock was not successful, because it was poisoned, then this is unrecoverable and we throw an error. If the future was not set, or the lock resulted in a TryLockError::WouldBlock error, then we run a pending job and attempt the whole procedure again.
In a nutshell, wait() will be stuck in a loop, running pending jobs, as long as the job is not completed, thus effectively blocking the calling job and progressing the entire job system. With this taken care of, what else might be missing from this job system? Well...
JobCell
At this point, I thought I was done with the job system. I seriously didn't expect that Rusts borrow checker would be a major killjoy. I've spent already a lot of time and effort to get to this point. But then I tried using it in my main loop, and the compiler simply said no.

The entire purpose of jobs is that they can take stuff, like objects or references, and then do work on them. A job will probably mutate data, or simply just immutably reference it to generate new state. But here's the last obstacle: Because the entire job system stores everything statically, thanks to its singleton-like nature, everything that is moved into a job must be statically borrowed. Something that is locally owned or referenced cannot be borrowed for a static lifetime. As much as the compiler is concerned, if a reference is moved into a job, it enters the nirvana, never to return. And the compiler simply doesn't allow that.
A workaround must be found.
To overcome this problem, I really had to scrape the bottom of the barrel. I have tested numerous solutions, all of which weren't satisfactory. Either I'd took a major performance hit, or the solution would panic randomly, or I'd introduce undefined behavior. Nothing worked, and prototype after prototype failed.
Before you say it, no, Arc<Mutex<T>> does NOT work. Remember what I've written in the previous section JobFuture: If a mutex were to block, then the entire worker thread blocks, meaning no progress will be made. I could write a spinlock around try_lock(), but this really isn't practical. Even if I were to create an elegant interface to spinlock a mutex, a spinlock still adds major overhead, which simply isn't worth it for just passing a single value into a job. This is especially true when I plan to spawn numerous jobs, all of which may reference their outside in one way or another.
What I want is an easy way to pass things into a job, with no overhead at all. Eventually, this led me to UnsafeCell, and a much much deeper understanding of how Rusts ownership rules work.
First, let's tackle mutable references, because as you will see shortly, these are actually quite easy to work around. I was expecting that these are the difficult ones, but with a little hack they were pretty trivial to solve. Instead of passing a mutable reference into a job, you can simply pass ownership into the job.
Test your knowledge! Does the following code compile?
struct MyInt {
value: i32,
}
struct Wrapper(MyInt);
fn consume(_: MyInt) {}
fn main() {
let wrapper = Wrapper(MyInt { value: 42 });
consume(wrapper.0);
println!("my current value is: {}", wrapper.0.value);
}
Hover to reveal the answer:
No, this doesn't compile. That should come as no surprise. We are moving a value out of wrapper! If you are accustomed to Rust, this should stick out like a sore thumb, and you would immediately realize that passing a &mut into consume() is probably what you wanted in the first place.
But what about this one? Does this compile?
struct MyInt {
value: i32,
}
struct Wrapper(MyInt);
fn consume(_: MyInt) {}
fn main() {
let mut wrapper = Wrapper(MyInt { value: 42 });
consume(wrapper.0);
wrapper.0 = MyInt { value: -13 };
println!("my current value is: {}", wrapper.0.value);
}
Hover to reveal the answer:
Yes, this does actually compile. This surprised me when I first saw this. We are still moving a value out of wrapper, just like the first code snippet, so why does it compile? The reason why the first one didn't compile is not really because we moved something out. Rather, we tried to use a value which was already moved. If you remove the println!() in the first example, we are not using wrapper after its move and the code compiles just fine. This implies that it's A-okay to move child values out from a parent. We just gotta replace it before we use it again. Instead of replacing it with an arbitrary value, we can replace it with the value we moved out! Remember that the JobFuture allows us to return something from a job. Any ownership that we may pass into a job we can return afterwards.
To illustrate this technique, here's an excerpt of my input logic, showcasing the part of the keyboard job:
pub fn run(
&mut self,
mut current: InputData, //🅐
previous: Ref<InputData>, //🅑
_frame: Ref<FrameData>,
) -> (InputData, GameloopState) { //🅒
let current_keyboard = current.keyboard; //🅓
...
let keyboard_future = job_system::submit(move || {
let mut keyboard = current_keyboard; //🅔
let gameloop_state = update_keyboard(
&mut keyboard,
...
);
(keyboard, gameloop_state) //🅕
});
...
let (new_keyboard, new_gameloop_state) = keyboard_future.wait(); //🅖
...
current.keyboard = new_keyboard; //🅗
...
(current, new_gameloop_state)
}
Ignore Ref for a moment 🅑. It most definitely is not the Ref you are currently thinking about. We will talk about it in a second.
Notice how the run() function takes ownership of an InputData object 🅐. It also returns an InputData object 🅒. This method alone is already demonstrating the technique. It takes ownership of InputData and later returns it. The first thing we do is to pass ownership of current.keyboard to a local variable 🅓. Then we move the local variable and ownership into the job 🅔. Now the job owns the keyboard and can mutate it however it wants. With an additional gameloop_state, the job also returns the keyboard 🅕, such that when the job is awaited, the caller once again has the ownership of keyboard in a local variable 🅖. To satisfy the compiler, we move this local variable new_keyboard back into current.keyboard 🅗.
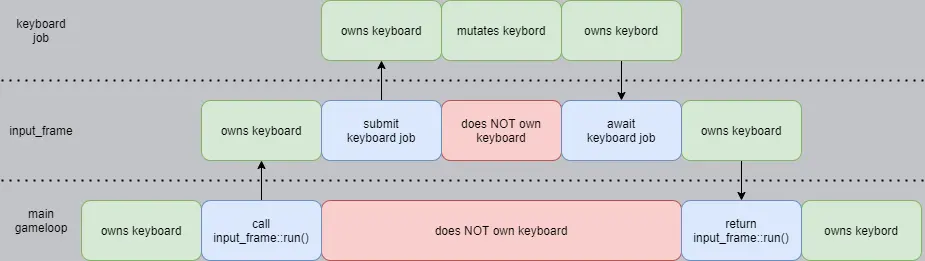
No ownership rules have been broken, and yet a job was fully able to mutate the value. Notice how in the diagram above, no green "owns keyboard" blocks overlap on the y axis. At every single point in time, there exists exactly one owner of keyboard, and as such the compiler is happy with this code.
This is cool, but why is this section called JobCell? Apparently, we don't even need a Cell-like structure to move things into a job! Up until this point I've talked about moving mutable values. But immutable references ain't so easy.
Immutable references are implicitly Copy. That means that if a single immutable reference exists, you can make as many immutable references as you like. We may pass a single immutable reference into a job, but returning it is fruitless. The job may create God knows how many references from it. A single return can never accommodate for all references that have been created. To say it bluntly: & is forbidden. No amount of ownership tricks can change this.
So we need a Cell-like struct afterall, that keeps track of all references somehow. Let me introduce my JobCell:

This JobCell can be in two states: Either simply JobCell, which allows you to make as many immutable references as you like. Or MutableJobCell, which allows you to mutate its content. To switch between the two states, some extra logic is required:
To switch from JobCell to MutableJobCell, all immutable references must be dead. To do this, we spinlock and call pending jobs as long as immutable references exist. This already imposes a restriction: Immutable references, created by the JobCell, are only allowed to be passed into a Job. If you were to create an immutable reference in the same thread where you want to mutate data, or attempt to store the reference somewhere indefinitely, then switching to the mutable state will livelock. A livelock is similar to a deadlock, except it is using up resources by spinning, instead of just going to sleep like a deadlock.
But if this restriction is taken care of, the spinlock ends and a MutableJobCell is created. To switch back to JobCell, all you have to do is to drop MutableJobCell. Now here comes a trick: Since MutableJobCell borrows JobCell mutably, the Rust compiler forbids you to use JobCell while MutableJobCell lives. This means as long as the JobCell is in its mutable state, no immutable references can be created. Not via JobCells interface, nor via Rusts default reference mechanics.
Enough theory, let's look at some code:
pub struct JobCell<T> {
value: UnsafeCell<T>,
refs: Arc<AtomicUsize>,
}
pub struct MutableJobCell<'a, T> {
value: &'a UnsafeCell<T>,
}
pub struct Ref<T> {
value: NonNull<T>,
refs: Arc<AtomicUsize>,
_boo: PhantomData<T>,
}
Here we have all structs to make the magic work. JobCell is a simple wrapper around UnsafeCell, but it additionally keeps count of its current references via an AtomicUsize. As mentioned previously, MutableJobCell stores a reference to an UnsafeCell, instead of straight up owning it. This directly leads to the mechanism, that JobCell cannot be used while MutableJobCell lives. Finally, we need to mimic &, by wrapping a pointer into a struct called Ref. Since this wrapper is its own thing, and syntactically independent from JobCell, the compiler thinks that client code owns it. To ensure that Ref mimics an immutable reference, only Deref will be implemented on it. It also doesn't implement any methods that could mutate its state in any way. Additionally, Ref stores a counter of all alive references. This counter is increased when Ref is being cloned, or decreased when Ref is being dropped. And because of some compiler optimization aliasing safety shenanigans tic-tac-toe i-don't-know-what-i-am-talking-about, Ref must also store a PhantomData.
impl<T> JobCell<T> {
/// ⚠️ don't put this in an `Rc` or `Arc` ⚠️
///
/// this cell is intended to have only one owner, who can mutate it
pub fn new(value: T) -> Self {
Self {
value: UnsafeCell::new(value),
refs: Arc::new(AtomicUsize::new(0)),
}
}
/// ⚠️ this method **WILL** livelock, when not all created `Ref`s are dropped ⚠️
pub fn as_mut(&mut self) -> MutableJobCell<T> {
while self.refs.load(Ordering::SeqCst) > 0 {
job_system::run_pending_job();
}
MutableJobCell { value: &self.value }
}
pub fn borrow(&self) -> Ref<T> {
self.refs.fetch_add(1, Ordering::SeqCst);
let value = unsafe { NonNull::new_unchecked(self.value.get()) };
Ref {
value,
refs: self.refs.clone(),
_boo: PhantomData,
}
}
}
Like I have said a thousand times already, the constructor should be fairly self-explanatory. It creates the UnsafeCell and the reference counter.
Since we went over the theory already, as_mut() should also be fairly straight forward. In a spinlock it constantly checks whether any references exist, and it runs pending jobs if they do. Only when no references exist, a MutableJobCell is created and returned.
If you've worked with Rusts pointers before, borrow() shouldn't be that difficult to understand either. But before we do any pointer magic, we increase the reference count by 1, indicating that from now on, an immutable reference exists. Then, we create a pointer to the data of the UnsafeCell. This value is never modified, or dereferenced mutably, so this is safe. Then we simply construct the Ref struct and return it.
To make my life easier, MutableJobCell implements one additional function:
impl<T> MutableJobCell<'_, T> {
pub fn replace(&mut self, value: T) -> T {
std::mem::replace(&mut *self, value)
}
}
This is a simple wrapper to replace the inner value of the JobCell.
Now let's implement some traits!
impl<T> Deref for MutableJobCell<'_, T> {
type Target = T;
fn deref(&self) -> &Self::Target {
unsafe { &*self.value.get() }
}
}
impl<T> DerefMut for MutableJobCell<'_, T> {
fn deref_mut(&mut self) -> &mut Self::Target {
unsafe { &mut *self.value.get() }
}
}
Deref and DerefMut for MutableJobCell are quite obvious, because we want to access and mutate the underlying data.
impl<T> Deref for Ref<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
unsafe { self.value.as_ref() }
}
}
Deref for Ref is also a no brainer. Very important: Ref does NOT implement DerefMut, otherwise this would be undefined behavior galore!
impl<T> Clone for Ref<T> {
fn clone(&self) -> Self {
self.refs.fetch_add(1, Ordering::SeqCst);
Self {
value: self.value,
refs: self.refs.clone(),
_boo: PhantomData,
}
}
}
To clone a Ref, we simply increase the reference counter and return a new Ref with the same data.
impl<T> Drop for Ref<T> {
fn drop(&mut self) {
self.refs.fetch_sub(1, Ordering::SeqCst);
}
}
Dropping a Ref decreases the reference counter. We don't need to free the pointer, because Ref doesn't semantically own it.
And that is basically it! To see the JobCell in action, here's some excerpt from my god job / main game loop:
pub fn run(mutgod_object: GodObject) -> Result<i32, String> {
let mut frame = JobCell::new(FrameData::default());
let mut current_input = InputData::default();
let mut previous_input = JobCell::new(InputData::default());
let mut current_logic = LogicData::default();
let mut previous_logic = JobCell::new(LogicData::default());
let mut current_output = OutputDatadefault();
let mut previous_output = JobCell::new(OutputData::default());
loop {
// update frame
frame.as_mut().bump();
// swap buffers
current_input = previous_input.as_mut().replace(current_input);
current_logic = previous_logic.as_mut().replace(current_logic);
current_output = previous_output.as_mut().replace(current_output);
// create references
let frame_for_input = frame.borrow();
let frame_for_logic = frame.borrow();
let frame_for_output = frame.borrow();
let previous_input_for_input = previous_input.borrow();
let previous_input_for_logic = previous_input.borrow();
let previous_logic_for_logic = previous_logic.borrow();
let previous_logic_for_output = previous_logic.borrow();
let previous_output_for_output = previous_output.borrow();
// submit jobs
let output_future = job_system::submit(move || {
output_frame::run(
current_output,
previous_output_for_output,
previous_logic_for_output,
frame_for_output,
)
});
let logic_future = job_system::submit(move || {
logic_frame::run(
current_logic,
previous_logic_for_logic,
previous_input_for_logic,
frame_for_logic,
)
});
let (new_input_data, input_state) =
god_object
.input_frame
.run(current_input, previous_input_for_input, frame_for_input);
// wait for jobs
let (new_logic_data, logic_state) = logic_future.wait();
let (new_output_data, output_state) = output_future.wait();
// update buffers
current_input = new_input_data;
current_logic = new_logic_data;
current_output = new_output_data;
...
}
}
Every buffer exists 2 times: Once as owned and once as JobCell. It's pretty much a front- and back-buffer system. The jobs that own a buffer, can modify them as much as they want. The jobs that only borrow the JobCell cannot mutate the buffer, and can only create new state which follows from the previous state.
Each iteration of the loop does the same: First, it switches each JobCell to MutableJobCell by calling as_mut() on them. If any immutable references exist at this point, these calls will spinlock and run all leftover jobs. Then the owned buffer and the JobCell buffer will be swapped. After that, all necessary Refs are created. Then these references are passed into the according jobs. Because SDL2 can only pump window events on the thread that spawned the window (which is my main thread), the input frame is not put into a job. And since we need to await it anyway, we might as well call it synchronously. After each job is done, we simply move ownership back, and another iteration of the loop is ready to be run.
Conclusion
What a buttload of garbage that I have written here. Does this junk even work?
Yes, surprisingly well actually. It was a lot of work to get this to a running state and I am quite amazed how stable it turned out in the end. There is no undefined behavior to my knowledge. How about performance? I get about the same number of frames as the previous single threaded prototype. This may sound bad, but this is probably due to the fact that this engine is very early in development. I simply don't have enough jobs yet to fully utilize its parallel ability. I have what? 4 jobs in total?! On my 12-core machine, that's hardly parallel at all! Anyway, be rest assured that this job system does indeed use 100% of CPU resources:
I have nothing else to say. My engine works steadily, and it didn't offer any nasty surprises. It simply brings me joy. But alas, only time will tell how well this system works. Remember: I am still the villain of the phrase "premature optimization is the root of all evil". This whole blogpost is the exemplification of premature optimization.
As for now, this job system is only a proof of concept. Now all I have to do is to use it, so I can experience firsthand how well it stacks up in the real world.
But until then, we'll hear from each other 🎶
|

| ◀ | Previous Post: Running Tests in Series in Rust |
| ▶ | More Programming related Posts |