
I found a Bug in my JobSystem
Writeup · Mar 17th, 2024
As a little joke, in my post about how I built my JobSystem, I included a little PHP script that counts the days since it was posted.
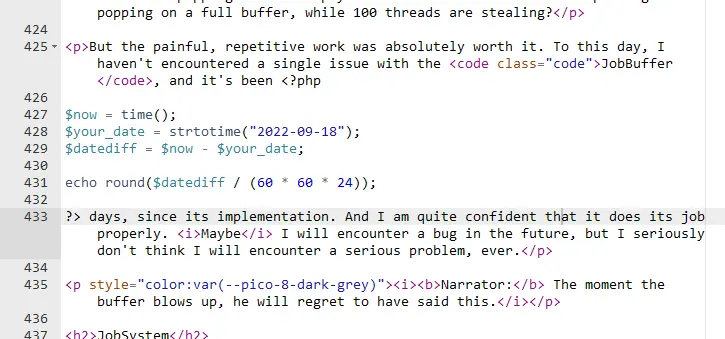
Unfortunately, I did run into a very severe bug, which is able to deadlock the entire system. Considering I made my JobSystem a big deal, I feel obligated to share you this rather interesting bug 😊
The Bug
Without going into the nitty gritty, here's a basic rundown of what the JobSystem does and how it works:
The JobSystem allows "Jobs" (function pointers, closures, lambdas, anonymous methods, or whatever your language of choice calls them) to be submitted to a buffer. Worker threads dequeue Jobs and execute them. With one worker per CPU core, this system is able to utilize all cores of your CPU, without the user ever needing to spawn additional threads for concurrency.
The submit function is global, and thus easily accessible. The pseudocode looks something like this:
pub fn submit(job: Job) -> JobFuture {
let future = JobFuture::new();
let wrapped_job = Job::new(() => {
let result = job();
future.set(result);
});
let success = enqueue_job(wrapped_job);
if (!success) {
wrapped_job();
}
return future;
}
First, a future is created. A future is a utility, that allows client code to wait and retrieve a Jobs return value, once it's done. The job is wrapped into another job, such that the future can be set. Then the wrapped job is enqueued. If the enqueue failed, the Job is simply invoked. Finally, the future is returned.
Unfortunately, this code is based on a flawed assumption: If a Job failed to be enqueued, then calling it immediately may lead to a deadlock.
Let me elaborate: Enqueuing can fail for 2 reasons: Either because the buffer is full, or because another thread holds a lock inside the buffer. These failures are by design. They enable a lock free behaviour and allow predictable performance. However, this comes with the consequence, that we may have a Job which was not enqueued. And now we need to decide what to do with that Job. When I wrote this code, I naively assumed I can just execute the Job. Afterall, as long as the system is making progress somehow, everything is fine. The client code should not care whether the Job is executed now or later.
But the following code breaks:
let future = JobFuture::new();
submit(() => {
future.wait();
});
future.set(42);
If an enqueue fails, this leads to the Job being executed directly. It's as if the call to submit isn't even there. The thread responsible for setting the future, the thread itself, will never set the future, because it's waiting on the future being set. Deadlock.
The Fix
Unfortunately, this has no satisfying solution. My engine is written in Rust, and to say it mildly, I am really struggling to get safe global state working. My latest prototype produces client code like this. It could be argued that the client code is unsound, and it shouldn't be legal in the first place, but because my latest prototype is somewhat promising, compromises have to be taken.
My current fix looks like this:
pub fn submit(job: Job) -> JobFuture {
let future = JobFuture::new();
let wrapped_job = Job::new(() => {
let result = job();
future.set(result);
});
while (true) {
let success = enqueue_job(wrapped_job);
if (success) {
break;
}
else {
run_pending_job();
}
}
return future;
}
It's very similar to the original code. Basically, submit the wrapped job until it succeeds. When the enqueue fails, call run_pending_job(). This function is a utility, allowing client code to run an enqueued Job. This is helpful, because if the current thread cannot make progress, the entire system can still make progress by working on something different. If no enqueued job exists, this function yields, freeing up the core for another thread.
This solution is not ideal, because this can still deadlock. It is still invoking Jobs, which may block the calling thread. There is always the possibility to simply not invoke a pending Job. But that would lead to a busy spinlock, using CPU resources without making progress. Admittedly, it would be safe, but there is the potential for a performance hit. Considering that my flawed clientcode only exists in debug builds of my engine, I am preferring the risk of a potential deadlock over a potential performance hit.
An more sophisticated solution would be to have a dedicated dispatcher. It would assign each Job an ID, telling them on what threads a Job is allowed to run on. But this requires more time and effort. And at the moment this bug is not justification enough for a dispatcher to exist. So I am sticking with the less likely, potential deadlock.
Conclusion
I am kind of amazed that it took this long until I found a major bug in my job system. In my previous post about the JobSystem, I emphasized how important it is to stress test something as critical and central as this. It only goes to show, how much good and extensive tests prevent bugs. Since then, I've also integrated miri in my testing, which gives me even more confidence in the stability of my system.
It also highlights once again how reliable Rust is. When I am working with C#, implementing something similar, I can't tell you how many times my code breaks just a few weeks or days after implementation. But nevertheless, my Rust code did in fact produce a bug. And unfortunately, that means I must take down my little PHP script on my original post 🥲
|

| ◀ | Previous Post: An even better Error Type |
| ▶ | Other Writeups |